



前言
在这一个月的学习中,又对文章进行了一次修改。在这段时间里我把一些没有意义的内容删除,又添加了我之间没有学习到的知识点,并尽量把说明放在前,案例放在后,方便大家一起学习。篇幅较长,建议大家收藏后分块阅读。

Node.js简介
已经掌握了那些技术
- HTML
- CSS
- JavaScript
浏览器中的JavaScript组成部分

浏览器中的javaScript运行环境
运行环境是指 代码正确运行所使用的必要环境

- V8引擎负责解析和执行JavaScript代码。
- 内置API是由
运行环境提供的特殊接口,只能在所属的运行环境中被调用。
什么是Node.js
Node.js 是一个基于 Chrome’s V8 的JavaScript运行环境。
Node.js的官方运行环境
Node.js是一个单线程的事件驱动的非阻塞性I/O模型
Node.js中的JavaScript运行环境

注意:
- 浏览器是 JavaScript 的前端运行环境。
- Node.js 是 JavaScript 的后端运行环境。
- Node.js 中无法调用 DOM 和 BOM 等浏览器内置 API。
Node.js可以做什么
Node.js 作为一个 JavaScript 的运行环境,仅仅提供了基础的功能和 API。然而,基于 Node.js 提供的这些基础能,很多强大的工具和框架如雨后春笋,层出不穷,所以学会了 Node.js ,可以让前端程序员胜任更多的工作和岗位:
1.基于 Express 框架
可以快速构建 Web 应用
可以构建跨平台的桌面应用
可以快速构建 API 接口项目
4 .读写和操作数据库、创建实用的命令行工具辅助前端开发、etc…
Node.js学习路径
-
JavaScript学习路径
JavaScript 基础语法 + 浏览器内置 API(DOM + BOM) + 第三方库(jQuery、art-template 等) -
Node.js学习路径
JavaScript 基础语法 + Node.js 内置 API 模块(fs、path、http等)+ 第三方 API 模块(express、mysql 等)
Node.js中的全局变量,全局对象
全局对象
所有模块都可以调用的对象
- global:表示Node所在的全局环境,类似于浏览器的window对象。
- process:该对象表示Node所处的当前进程,允许开发者与该进程互动。
- console:指向Node内置的console模块,提供命令行环境中的标准输入、标准输出功能。
全局函数
- 定时器函数:共有4个,分别是setTimeout(), clearTimeout(), setInterval(), clearInterval();
- require:用于加载模块;
- Buffer():用于操作二进制数据。
全局变量
- __filename:指向当前运行的脚本文件名。
- __dirname:指向当前运行的脚本所在的目录。
拓展:
除此之外,还有一些对象实际上是模块内部的局部变量,指向的对象根据模块不同而不同,但是所有模块都适用,可以看作是伪全局变量,主要为module, module.exports, exports等。
Node.js环境的安装
在Node.js中运行JavaScript文件
- 在当前文件夹中打开终端。
- 输入
node [文件名]或者nodemon[文件名]
LTS版本和Current版本
- LTS 为长期稳定版,对于
追求稳定性的企业级项目来说,推荐安装 LTS 版本的 Node.js。 - Current 为新特性尝鲜版,对
热衷于尝试新特性的用户来说,推荐安装 Current 版本的 Node.js。但是,Current 版本中可能存在隐藏的 Bug 或安全性漏洞,因此不推荐在企业级项目中使用 Current 版本的 Node.js。
监听事件EventEmitter类
通过引入events模块,并通过实例化EventEmitter类来绑定和监听事件。
// 引入 events 模块
var events = require('events');
// 创建 eventEmitter 对象
var eventEmitter = new events.EventEmitter();
//或者如下
var EventEmitter = require('events').EventEmitter;
var event = new EventEmitter();
绑定事件处理函数:.on
// 绑定事件及事件的处理程序
eventEmitter.on('eventName', eventHandler);
触发事件: .emit
// 触发事件
eventEmitter.emit('eventName');
只触发一次: .once
为指定事件注册一个单次监听器,即 监听器最多只会触发一次,触发后立刻解除该监听器,也就是说不管某个事件在将来被触发多少次,都只调用一次回调函数。
a.once('某个事件', function () {
//尽管事件会触发多次,但此方法只会执行一次
});
具体实例如下,创建入口文件,代码为:
// 引入 events 模块
var events = require('events');
// 创建 eventEmitter 对象
var eventEmitter = new events.EventEmitter();
// 创建事件处理程序
var connectHandler = function connected() {
console.log('连接成功。');
// 触发 data_received 事件
eventEmitter.emit('data_received');
}
// 绑定 connection 事件处理程序
eventEmitter.on('connection', connectHandler);
// 使用匿名函数绑定 data_received 事件
eventEmitter.on('data_received', function(){
console.log('数据接收成功。');
});
// 触发 connection 事件
eventEmitter.emit('connection');
console.log("程序执行完毕。");
//运行结果:
//连接成功。
//数据接收成功。
//程序执行完毕。
EventEmitter 的每个事件由一个事件名和若干个参数组成,事件名是一个字符串,通常表达一定的语义。对于每个事件,EventEmitter 支持 若干个事件监听器。当事件触发时,注册到这个事件的事件监听器被依次调用,事件参数作为回调函数参数传递。
//event.js 文件
var events = require('events');
var emitter = new events.EventEmitter();
emitter.on('someEvent', function(arg1, arg2) {
console.log('listener1', arg1, arg2);
});
emitter.on('someEvent', function(arg1, arg2) {
console.log('listener2', arg1, arg2);
});
emitter.emit('someEvent', 'arg1 参数', 'arg2 参数');
//运行结果:
//listener1 arg1 参数 arg2 参数
//listener2 arg1 参数 arg2 参数
error事件
EventEmitter 定义了一个特殊的事件 error,它包含了错误的语义,我们在遇到 异常的时候通常会触发 error 事件。当 error 被触发时,EventEmitter 规定如果没有响 应的监听器,Node.js 会把它当作异常,退出程序并输出错误信息。
我们一般要为会触发 error 事件的对象设置监听器,避免遇到错误后整个程序崩溃。例如:
var events = require('events');
var emitter = new events.EventEmitter();
emitter.emit('error');
//运行结果会显示出错误信息
fs文件系统模块
fs模块是Node.js官方提供的,用来操作文件的模块。它提供了一系列的方法和属性,用来满足用户对文件的操作需求。读取文件内容的函数有异步的fs.readFile()和同步的fs.readFileSync(),还有一些其他方法,比如创建文件等,下面用表格的方式列出一些常见的方法。
文件方法
文件的读取,写入,删除,复制,追加。
| 方法 | 描述 |
|---|---|
| fs.readFile(path[, options], callback) | 异步读取文件的全部内容 |
fs.writeFile(file,data[,options],callback) |
将数据异步写入文件,如果文件存在,这替换该文件。 |
| fs.writeFileSync(file,data[,options]) | 将数据同步写入文件,如文件已经存在则替换该文件。 |
fs.appendFile(path,data[,options],callback) |
异步的将数据追加到文件,如果该文件尚不存在,则创建该文件。 |
| fs.appendFileSync(file,data[,options]) | 同步的将数据追加到文件,如果该文件尚不存在,则创建该文件。 |
| fs.unlink(path,callback) | 异步删除文件 |
| fs.unlinkSync(path) | 同步删除文件 |
| fs.copyFile(src,dest[,flags],callback) | 异步的将src复制到dest。默认情况下,如果dest已经存在,则会覆盖。 |
| fs.copyFileSync(src,dest[,flags]) | 同步的将src复制到dest。默认情况下,如果dest已经存在,则会覆盖。 |
目录方法
文件夹的创建,删除,读取。
| 方法 | 描述 |
|---|---|
fs.mkdir(path[,options],callback) |
异步创建目录 |
| fs.mkdirSync(path[,options]) | 同步创建目录 |
| fs.rmdir(path[,options],callback) | 异步删除目录 |
| fs.rmdirSync(path[,options]) | 同步删除目录 |
| fsPromises.readdir(path[, options]) | 读取目录的内容。回调有两个参数(err,files),其中files是目录文件名的数组,不包含’.‘和’…’ |
| fs.readdirSync(path[, options]) | 同步读取目录下的文件 |
如果要在JavaScrirpt代码中,使用fs模块来操作文件,则需要先导入文件
const fs = require('fs')
Warning / 注意
在使用上面的方法时,最好去官方API文档里去查找具体用法。
读取指定文件中的内容
- fs.readFile( ) 的语法格式
使用fs.readFile()方法,可以读取指定文件中的内容,语法格式如下:
fs.readFile(path[,options],callback)
解读参数:
- 参数一:
必选参数,字符串,表示文件的路径 - 参数二:可选参数,表示以什么
编码格式来读取文件 - 参数三:
必选参数,文件读取完成后,通过回调函数拿到读取的结果。
//1.导入fs模块
const fs = require('fs')
//2.调用1 fs.readFile() 方法获取文件
//3.回调函数,拿到读取失败和成功的结果 err dataStr
fs.readFile('./1.txt', 'utf-8', function (err, dataStr) {
//2.1 打印失败结果
//如果读取成功,则err的值为null
//如果读取失败,则err的值为 错误对象 dataStr的值为undefined
console.log(err);
console.log('-------');
//2.2 打印成功结果
console.log(dataStr);
})
Tips / 提示:
如果
读取成功,则err的值为null
如果读取失败,则err的值为错误对象dataStr的值为undefined
判断文件是否读取成功
可以判断err文件对象是否为null

向指定文件中写入内容
- fs.writeFile()的语法格式
使用fs.writeFile()方法,可以向指定文件写入内容,语法格式如下:

参数解读:
- 参数1:
必须参数,需要指定一个文件路径的字符串,表示文件存放路径 - 参数2:
必选参数,表示要写入的内容 - 参数3:可选参数,表示以什么格式写入文件内容,默认值是utf-8
- 参数4:
必选参数,文写入完成后的回调函数。
//1. 导入文件系统模块
const fs = require('fs')
//2. 调用fs.writeFile( ) 方法,写入文件内容
fs.writeFile(__dirname+'./2.txt', 'HelloNode.js', function (err) {
//2.1 文件写入成功,err返回null
//2.2 文件写入失败,err返回错误对象
console.log(err);
})
//ES6写法
fs.writeFile(__dirname + '../file/exanple.txt', 'HelloNode.js', err => console.log(err))
注意:
- 文件写入成功,err返回null
- 文件写入失败,err返回错误对象

Expand / 拓展
writeFile只能去
新建文件,不能新建文件夹。如果文件已经存在,新内容就会覆盖旧内容。
判断文件是否读取成功
可以判断 err 对象是否为 null,从而知晓文件写入的结果:

const fs = require('fs')
fs.readFile('./1.txt', 'utf-8', function (err, dataStr) {
if (err) {
return console.log('文件读取失败!' + err.message);
}
console.log('读取文件成功!' + dataStr);
})

文件追加
const fs = require('fs')
const path = require('path')
fs.appendFile(path.join(__dirname, '../file/1.txt'), '这是追加的数据', (err, dataStr) => {
if (err) {
console.log('add fail');
} else {
console.log('add done' + dataStr);
}
})
结果
程序运行完毕,会在1.txt文件中,追加数据,文件原来的数据还在。
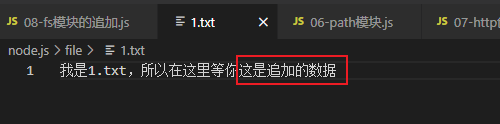
注意
上面回调函数中的
dataStr返回的是undefined,成功时将使用undefined履行。
目录创建
const fs = require('fs')
fs.mkdir('./datas', (err) => {
if (err) {
return console.log("目录创建失败" + err.message);
} else {
console.log("目录创建成功");
}
})
结果
运行成功后,会在当前目录创建一个datas文件夹。
异步编程和同步编程
在JavaScript 或 Node.js中,代码分成两种同步代码与异步代码
在JavaScript或Node.js中,解析器总是先执行同步的代码,同步代码结束后,再执行异步代码的回调。
Node.js的异步编程的直接体现就是通过回调函数来实现的,
注意:同步编程依赖于回调来实现,但不代表使用了回调函数就异步化了。
非阻塞代码的实现,即异步编程。
异步编程
const fs = require('fs')
//异步编程
fs.readFile(__dirname + '/../file/example.txt', 'utf-8', (err, data) => {
if (err) {
console.log(err);
}
console.log(data); //执行顺序2
});
console.log("END1"); //执行顺序1
同步编程
const fs = require('fs')
const con = fs.readFileSync(__dirname + '/../file/example.txt') //执行顺序1
console.log(con)
console.log("END2"); //执行顺序2
异步编程:在读文件的时候可以先做其他的,提高性能。
同步编程:必须等文件读取完成才可以做其他的。在读取文件的时候程序一种处于堵塞状态。
案例
const fs = require('fs')
//异步编程
fs.readFile(__dirname + '/../file/example.txt', 'utf-8', (err, data) => {
if (err) {
console.log(err);
}
console.log(data); //执行顺序5
});
console.log("END1"); //执行顺序1
//同步编程
console.log('---------------分割线-----------------'); //执行顺序2
const con = fs.readFileSync(__dirname + '/../file/example.txt')
console.log(con) //执行顺序3
console.log("END2"); //执行顺序4
- 执行结果

readFileSync默认返回的是
Buffer对象,可以在对象后面使用toString方法来转换成字符串,或者在读取文件时,指定为’utf-8’的格式。
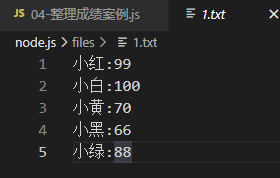
考试成绩整理(案例)1
使用 fs 文件系统模块,将素材目录下成绩.txt文件中的考试数据,整理到成绩-ok.txt文件中。
核心实现步骤
- 导入需要的fs文件系统模块
- 使用fs.readFile( ) 方法,读取素材目录下的
成绩.txt文件 - 判断文件是否读取失败
- 文件读取成功,处理成绩数据
- 将处理好的数据,调用fs.writeFile()方法,写入到新文件中。
fs 模块 - 路径动态拼接的问题
- 在使用 fs 模块操作文件时,如果提供的操作路径是以 ./ 或 …/ 开头的相对路径时,很容易出现路径动态拼接错误的问题。
- 原因:代码在运行的时候,会以执行 node 命令时所处的目录,动态拼接出被操作文件的完整路径。
- 解决方案:在使用 fs 模块操作文件时,直接提供完整的路径,不要提供 ./ 或 …/ 开头的相对路径,从而防止路径动态拼接的问题。
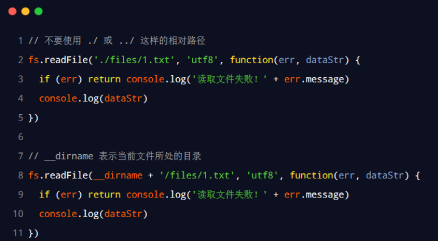
核心代码
const fs = require('fs')
fs.readFile('./成绩.txt', 'utf-8', function (err, dataStr) {
if (err) {
return console.log('文件读取失败!' + err.message);
}
// console.log('文件读取成功!' + dataStr);
//对数据进行分隔
const arrOld = dataStr.split(' ')
console.log(arrOld);
//循环分隔后的数组,对每一项数据,进行字符串替换操作
const arrnew = []
arrOld.forEach(item => {
arrnew.push(item.replace('=', ':'))
});
//这个循环遍历也可以这样写
// arrOld.forEach((v,i)=>{
// arrnew.push(v.replace('=',':'))
// })
console.log(arrnew);
//把数组中的每一项,进行合并,得到一个新数组
const Str = arrnew.join('\r\n')
//将数据写入1.txt文件中
fs.writeFile('./1.txt', Str, function (err) {
if (err) {
return console.log('文件写入失败!' + err.message);
}
return console.log('文件写入成功!');
})
})
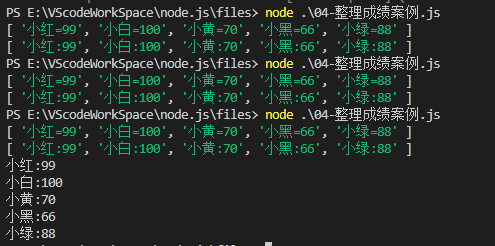
考试成绩整理(案例)2
将成绩单.txt中的数据转换成对象格式,并保存再另一个文件中。
张三=98 李四=96 王五=95 转换成 {"张三":"98","李四":"96","王五":"95"}
核心代码
const fs = require('fs')
const path = require('path')
//创建一个结果对象,用来保存输出的结果
var obj = {}
fs.readFile(path.join(__dirname, '../file/成绩单.txt'), 'utf-8', (err, dataStr) => {
if (err) {
console.log(`文件读取失败:${err.message}`);
} else {
let str = []
//将对象切割为数组
str = dataStr.split(" ")
str.forEach((v, i) => {
// v.split('=')[0]拿到的是属性名,v.split('=')[1]拿到的是属性值
obj[v.split('=')[0]] = v.split('=')[1]
})
var st = JSON.stringify(obj)
console.log(st);
fs.writeFile(path.join(__dirname, '../file/成绩单处理结果.txt'), st, "utf8", (err) => {
if (err) {
console.log('文件写入失败');
}
})
}
})
/**
* 结果
* {
* 张三:98,
* 李四:96,
* 王五:95
* }
*/
注意
- 首先注意作用域问题,明确对象obj的作用范围。在第一次做的时候作用域弄错,导致obj本来就是个空对象,还用JSON.stringify(obj)转字符串,结果出来就是一个大括号,这个问题需要注意。
提示
obj[v.split('=')[0]]=v.split('=')[1]相当于对象中的
对象[属性名]=属性值的方式来添加属性。
拓展
对象转字符串
JSON.stringify(obj)字符串转对象
JSON.parse(st)
path路径模块
path模块是Node.js官方提供的,用来处理路径的模块,它提供了一系列的方法和恶属性,用来满足用户对路径的需求。
| 方法 | 描述 |
|---|---|
| path.normalize(path) | 规范化路径,注意’…‘和’.’ |
| path.join() | 用来将多个路径片段拼接成一个完整的字符串。 |
| path.basename(path[,ext]) | 用来从路径字符串中,将文件名称解析出来。 |
| path.resolve([…paths]) | 将路径解析为绝对路径 |
| path.isAbsolute(path) | 判断参数path 是否是绝对路径 |
| path.relative(from,to) | 用于将路径转为相对路径 |
| path.dirname(path) | 返回路径中代表文件夹的部分 |
| path.extname(path) | 返回路径中文件的扩展名,即路径中最后一个’.'之后的部分 |
| path.parse(pathString ) | 返回路径字符串的对象格式 |
| path.format(pathObject) | 从对象中返回路径字符串(path.parse相反) |
Tip / 小建议
在使用上面方法时,最好先去官方文档查阅。
如果要在javascript代码中,使用path模块来处理路径,必须先导入:
const path = require('path')
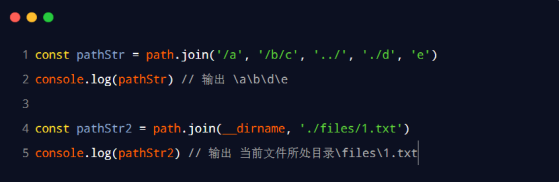
路径拼接
path.join()的语法格式
path.join()方法,可以多个路径片段拼接为完整的路径的字符串,语法格式如下:
path.join([...paths])
参数解读:
- …paths < string>路径片段的序列
- 返回值:< string>
path.join()的代码示例
使用path.join()方法,可以把多个路径片段拼接为完整的路径字符串:
注意:
今后凡是涉及到路径拼接的操作,都要使用path.join()方法进行处理。不要直接使用 + 进行字符串的拼接。
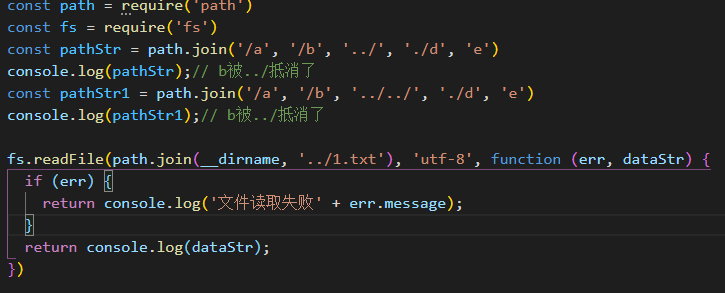
扩展
注意:上图中的 __ dirname是文件的上一目录
node在执行的时候,会以当前目录进行执行,导致相对路径出现错误。
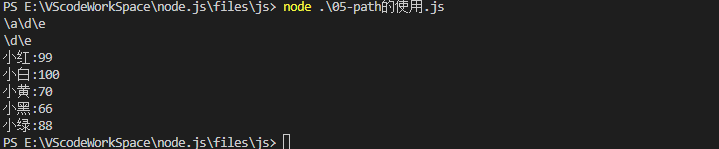
获取路径中的文件名
path.basename() 的语法格式
使用 path.basename() 方法,可以获取路径中的最后一部分,经常通过这个方法获取路径中的文件名,语法格式如下:
path.basename(path[,ext])
参数解读:
- path < string > 必选参数,表示一个路径的字符串
- exit < string > 可选参数 ,表示文件扩展名
- 返回: < string > 表示路径中的最后一部分
path.basename() 的代码示例
使用 path.basename() 方法,可以从一个文件路径中,获取到文件的名称部分
const path = require('path')
const furl = '../file/1.txt';
const fullName = path.basename(furl);
const exatName = path.basename(furl, '.txt');
console.log(fullName);
console.log(exatName);
//__dirname
console.log(__dirname);

获取路径中的文件扩展名
path.extname() 的语法格式
path.extname(path)
参数解读:
- path < string > 必选参数,表示一个路径的字符串
- 返回: < string > 返回得到的扩展名字符串
path.extname() 的代码示例
使用 path.extname() 方法,可以获取路径中的扩展名部分:
const fs = require('path')
const ftext = '/a/b/c/index.html' //路径字符串
const fext = fs.extname(ftext)
console.log(fext);

综合案例- 时钟案例
案例要实现的内容
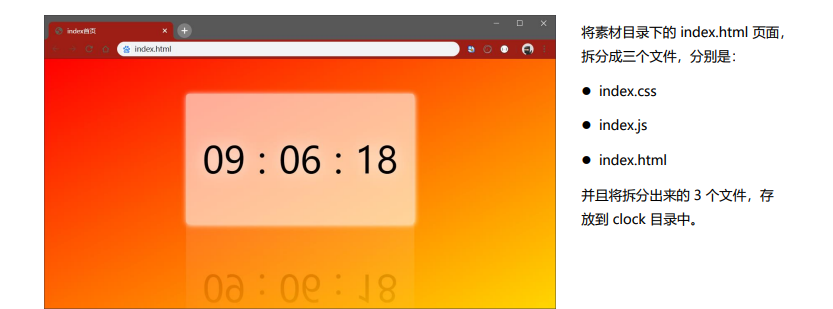
案例实现步骤
- 创建两个正则表达式,分别用来匹配 < style > 和 < script > 标签
- 使用 fs 模块,读取需要被处理的 HTML 文件
- 自定义 resolveCSS 方法,来写入 index.css 样式文件
- 自定义 resolveJS 方法,来写入 index.js 脚本文件
- 自定义 resolveHTML 方法,来写入 index.html 文件
- 导入模块
//导入fs模块
const fs = require('fs')
//导入path模块
const path = require('path')
- 定义正则表达式
// 定义正则表达式
const regStyle = /<style>[\s\S]*<\/style>/
const regScript = /<script>[\s\S]*<\/script>/
- 处理文档
//使用fs模块读取需要处理的html文件
fs.readFile(path.join(__dirname, './clock/index.html'), 'utf-8', (err, dataStr) => {
//读取HTML文件失败
if (err) return console.log('文件读取失败!' + err.message)
resolveCSS(dataStr)
//读取HTML文件成功后,调用方法
resolveJS(dataStr)
resolveHTML(dataStr)
})
function resolveCSS(htmlStr) {
//使用正则表达式来提取出style标签里面的内容
const r1 = regStyle.exec(htmlStr)
//将提取出来的样式字符串,做进一步的处理(替换处理)
const newCSS = r1[0].replace('<style>', '').replace('</style>', '')
fs.writeFile(path.join(__dirname, './clock/index.css'), newCSS, err => {
if (err) {
return console.log('写入css样式失败!' + err.message);
}
console.log('写入CSS样式成功');
})
}
function resolveJS(htmlStr) {
//使用正则表达式提取出 script标签里面的内容
const r2 = regScript.exec(htmlStr)
const newJS = r2[0].replace('<script>', '').replace('</script>', '')
fs.writeFile(path.join(__dirname, './clock/index.js'), newJS, err => {
if (err) {
return console.log('写入Js失败!' + err.message);
}
console.log('写入JS成功');
})
}
//定义处理 HTML 结构的方法
function resolveHTML(htmlStr) {
const newHTML = htmlStr
.replace(regStyle, '<link rel="stylesheet" href="./index.css" />')
.replace(regScript, '<script src="./index.js"></script>')
//接下来写入文档中
fs.writeFile(path.join(__dirname, './clock/index.html'), newHTML, err => {
if (err) {
return console.log('html文件写入失败' + err.message);
}
return console.log('html文件写入成功!');
})
}
注意:
- fs.writeFile()方法只能用来创建文件,不可以用来创建路径。
- 重复调用fs.writeFile()写入同一个文件,新写入的会覆盖之前的旧内容。
- node读取文件时异步任务,所以会造成打印顺序不同。
URL模块
url模块提供了URL解析和分析工具。
- 例子:
http://user:pass@host.com:8080/p/a/t/h?query=string#hash
| 参数 | 描述 | 示例 |
|---|---|---|
| href | 解析前的完整原始url,协议名和主机名已经转为小写 | http://user:pass@host.com:8080/p/a/t/h?query=string#hash |
| protocol | 请求协议,小写 | http: |
| slashes | 协议的":“号后面是否有”/" | true or false |
| host | URL主机名,包括端口信息,小写 | ‘host.com:8080’ |
| auth | URL中的认证信息 | ‘user:pass’ |
| hostname | 主机名,小写 | ‘host.com’ |
| port | 主机的端口号 | ‘8080’ |
| pathname | URL中路径 | ‘/p/a/t/h’ |
| search | 查询对象,即:queryString,包括之前的问号"?" | ‘?query=string’ |
| query | 查询字符串中的参数部分(问号后面部分字符串) | 'query=string’or |
| hash | 锚点部分(即:"#"及之后的部分) | ‘#hash’ |
如果要在javascript代码中,使用url模块来处理url,必须先导入:
const url = require('url')
将url转换成对象
url.parse()方法用于解析URL对象,解析后统一返回一个JSON对象
url.parse(urlStr[,parseQueryString] [,slashesDenoteHost])
扩展
第二个参数设置为ture时,会使用querystring模块来解析url中查询字符串部分,默认为false.
// http://127.0.0.1:8080/list?username=zs&password=123 浏览器地址栏输入
var urlogj = url.parse(req.url, true)
var pathname = urlogj.pathname
console.log(urlogj.query.username);
console.log(urlogj.query.password);
--- 控制台输出 ---
Url {
protocol: null,
slashes: null,
auth: null,
host: null,
port: null,
hostname: null,
hash: null,
search: '?username=zs&password=123',
query: [Object: null prototype] { username: 'zs', password: '123' },
pathname: '/list',
path: '/list?username=zs&password=123',
href: '/list?username=zs&password=123'
}
server running at http://127.0.0.1:8080
zs
123
注意
从输出结果可以看到,pares的第二个参数为true时,会解析查询字符串的url,并用使用对象将数据输出。
将对象格式化为URL字符串
url.format(urlObj)用于格式化URL对象。输入一个URL对象,返回格式化后的URL字符串。
分隔字符串案例
需求:将’username=zs&password=123’ 转换成 {username:“zs”,password:123} 输出
//'username=zs&password=123' {username:"zs",password:123}
var str = 'username=zs&password=123';
//str.split() 按照标识,将字符串切分成数组
var arr = str.split("&")
var obj = {}
arr.forEach((v, i) => {
obj[v.split("=")[0]] = v.split("=")[1]
})
console.log(obj);
提示
使用字符串的split()将字符串转换为数组,再次分隔得出结果,注意上面案例
对象[属性名]的方式。v.split(“=”)[0]取得属性名,v.split(“=”)[1]取得属性值
http知识
概念
http协议即超文本传送协议,它规定了客户端与服务器之间进行的网页内容传输时,所必须遵守的传输格式。(是一种约定规则)
请求(请求报文)
客户端发起的请求叫做HTTP请求,客户端发送到服务器的消息叫做HTTP请求消息,又叫做HTTP请求报文。
请求消息的组成
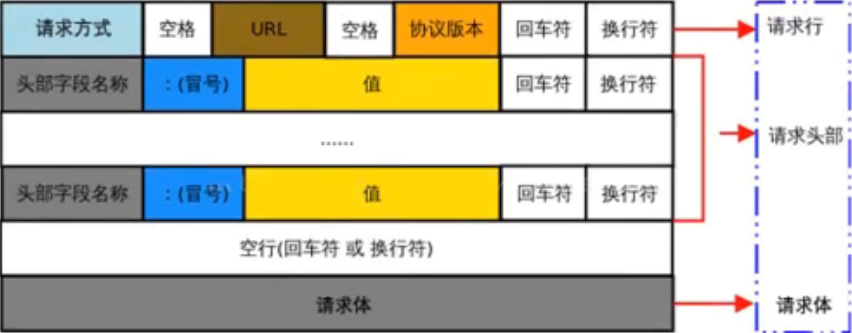
HTTP请求消息由请求行,请求头,空行,请求体4个部分组成。
| 头部字段 | 说明 |
|---|---|
| Host | 要请求的服务器域名 |
| Connection | 客户端与服务器的连接方式(close或keep-alive) |
| Content-Length | 用来描述请求体的大小 |
| Accept | 客户端可识别的响应内容类型列表 |
| User-Agent | 产生请求的浏览器类型 |
| Content-Type | 客户端告诉服务器实际发送的数据类型 |
| Accept-Encoding | 客户端可接受的内容压缩编码形式 |
| Accept-Language | 用户期望获得的自然语言的优先顺序 |
- 请求行:由请求方式(get, post),url(/login?)和HTTP协议版本3个部分组成,他们之间使用空格隔开。
- 请求头部:用来描述客户端的基本信息,从而把客户端的相关信息告诉服务器。请求头部由多行 键/值对 组成,每行的键和值之间用英文的冒号隔开。
- 空行:最后一个请求头字段后面是空行,通知服务器请求头部到此结束。请求消息中的空行,用来分隔请求头部与请求体。
- 请求体:请求体中存放的,是要通过POST方式提交到的服务器数据。只有POST请求才有请求体,GET请求没有请求体。
响应(响应报文)
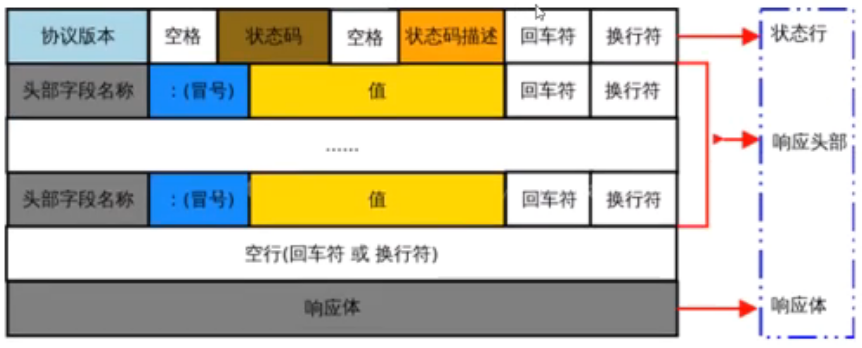
响应消息的组成
提示
- 状态行:由HTTP协议,转态码和状态码的描述文本3个部分组成,他们之间用空格隔开。
- 响应头部:用来描述服务器的基本信息。响应头部由多行键/值对组成,每行的键和值之间用英文的冒号隔开。
- 空行:在最后一个响应头部文字结束之后,会紧跟一个空行,用来通知客户端响应头部至此结束。响应消息中的空行,用来分隔头部和响应体。
- 响应体:它内部存放的,是服务器响应给客户端的资源内容。
HTTP请求的方法
HTTP请求方法,属于HTTP协议中的一部分,请求方法的作用是:用来表明要对服务器上的资源执行的操作。最常用的请求方法是GET和POST
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | (查询)发送请求来获得服务器上的资源,请求体中不会包含请求数据,请求数据放在协议头中。 |
| 2 | POST | (新增)向服务器提交资源(例如提交表单或上传文件),数据被包含在请求体中提交给服务器 |
| 3 | PUT | (修改)向服务器提交资源,并使用提交的新资源,替换掉服务器对应的旧数据 |
| 4 | DELETE | (删除)请求服务器删除指定的资源 |
| 5 | HEAD | HEAD方法请求一个与GET请求的响应相同的响应,但没有响应体。 |
| 6 | OPTIONS | 获取http服务器支持的http请求方法,允许客户查看服务器的性能,比如ajax跨域时候的预检等。 |
| 7 | CONNECT | 建立一个到由目标资源标识的服务器的隧道。 |
| 8 | TRACE | 沿着到目标资源路径执行一个环回测试,主要用来测试或诊断。 |
| 9 | PATCH | 是对put方法的补充,用来对已知资源进行局部更新 |
响应的状态码
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求继续执行操作 |
| 2** | 成功,操作被成功接受并处理 |
| 3** | 重定向,需要进一步的操作完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发现了错误 |
使用http模块创建服务器
客户端、服务器
在网络节点中,负责消费资源的电脑,叫做客户端
负责对外提供网络资源的电脑,叫做服务器。
服务器与普通电脑的区别
服务器需要安装web服务器的软件,普通电脑安装了web服务器软件,普通电脑就变成了web服务器。例如Apache软件。
服务器相关概念
- IP地址
IP 地址就是互联网上每台计算机的唯一地址,因此 IP 地址具有唯一性。如果把“个人电脑”比作“一台电话”,那么“IP地址”就相当于“电话号码”,只有在知道对方 IP 地址的前提下,才能与对应的电脑之间进行数据通信。
IP 地址的格式:通常用“点分十进制”表示成(a.b.c.d)的形式,其中,a,b,c,d 都是 0~255 之间的十进制整数。例如:用点分十进表示的 IP地址(192.168.1.1)
注意:
互联网中每台 Web 服务器,都有自己的 IP 地址,例如:大家可以在 Windows 的终端中运行pingwww.baidu.com 命令,即可查看到百度服务器的 IP 地址。- 在开发期间,自己的电脑既是一台服务器,也是一个客户端,为了方便测试,可以在自己的浏览器中输入 127.0.0.1 这个IP 地址,就能把自己的电脑当做一台服务器进行访问了.
域名和域名服务器
尽管 IP 地址能够唯一地标记网络上的计算机,但IP地址是一长串数字,不直观,而且不便于记忆,于是人们又发明了另一套字符型的地址方案,即所谓的域名(Domain Name)地址。
IP地址和域名是一一对应的关系,这份对应关系存放在一种叫做域名服务器(DNS,Domain name server)的电脑中。使用者只需通过好记的域名访问对应的服务器即可,对应的转换工作由域名服务器实现。因此,域名服务器就是提供 IP 地址和域名之间的转换服务的服务器。
注意:
- 单纯使用IP地址,互联网中的电脑也能够正常工作。但是有了域名的加持,能让互联网的世界变得更加方便。
- 在开发测试期间,
127.0.0.1对应的域名是localhost,它们都代表我们自己的这台电脑,在使用效果上没有任何区别。
- 端口号
计算机中的端口号,就好像是现实生活中的门牌号一样。通过门牌号,外卖小哥可以在整栋大楼众多的房间中,准确把外卖送到你的手中。
同样的道理,在一台电脑中,可以运行成百上千个 web 服务。每个 web 服务都对应一个唯一的端口号。客户端发送过来的网络请求,通过端口号,可以被准确地交给对应的 web 服务进行处理。

创建最基本的 web 服务器
创建 web 服务器的基本步骤
- 导入http模块
- 创建web服务器实例
- 为服务器实例绑定
request事件,监听客户的需求 - 启动服务器
1. 导入 http 模块
// 1. 导入 http 模块
const http = require('http')
2. 创建 web 服务器实例
调用http.createServer()方法,即可快速创建一个 web 服务器实例
// 2. 创建 web 服务器实例
const server = http.createServer()
3.为服务器实例绑定 request 事件
// 3. 为服务器实例绑定 request 事件,监听客户端的请求
server.on('request', function (req, res) {
console.log('Someone visit our web server.')
})
4.启动服务器
调用服务器实例的.listen()方法,即可启动当前的web服务器实例:
// 4. 启动服务器
server.listen(8080, () => {
console.log('server running at http://127.0.0.1:8080')
})
req请求对象
只要服务器接收到了客户端的请求,就会调用通过server.on()为服务器绑定的 request 事件处理函数。如果想在事件处理函数中,`访问与客户端相关的数据或属性,可以使用如下的方式:
小提示
req对象有很多方法和属性,可以在控制台输入查看。
最常用的是
req.url,可以获取到url信息
res响应对象
在服务器的requset事件处理函数中,如果想访问与服务器相关的数据或属性,可以使用如下的方式。
server.on('request', (req, res) => {
// req.url 是客户端请求的 URL 地址
const url = req.url
// req.method 是客户端请求的 method 类型
const method = req.method
const str = `Your request url is ${url}, and request method is ${method}`
console.log(str)
// 调用 res.end() 方法,向客户端响应一些内容
res.end(str)
})
解决中文乱码
通过 res.setHeader参数,设置响应头,解决中文乱码问题。
const http = require('http')
const server = http.createServer()
server.on('request', (req, res) => {
// 定义一个字符串,包含中文的内容
const str = `您请求的 URL 地址是 ${req.url},请求的 method 类型为 ${req.method}`
// 调用 res.setHeader() 方法,设置 Content-Type 响应头,解决中文乱码的问题
res.setHeader('Content-Type', 'text/html; charset=utf-8')
// res.end() 将内容响应给客户端
res.end(str)
})
server.listen(80, () => {
console.log('server running at http://127.0.0.1')
})
注意:
解决中文乱码问题的解决方案是固定的。
charset和utf-8中间不能有空格,否则就会出现中文乱码。
http模块
什么是http模块
http 模块是 Node.js 官方提供的、用来创建 web 服务器的模块。通过 http 模块提供的 http.createServer() 方法,就能方便的把一台普通的电脑,变成一台 Web 服务器,从而对外提供 Web 资源服务。
- 使用
const http = require('http')
http模块的作用
服务器和普通电脑的区别在于,服务器上安装了 web 服务器软件,例如:IIS、Apache 等。通过安装这些服务器软件,就能把一台普通的电脑变成一台 web 服务器。
在 Node.js 中,我们不需要使用 IIS、Apache 等这些第三方 web 服务器软件。因为我们可以基于 Node.js 提供的http 模块,通过几行简单的代码,就能轻松的手写一个服务器软件,从而对外提供 web 服务。
根据不同的url响应不通的html内容
1. 核心实现步骤
- 获取
请求的url地址 - 设置
默认的相应内容为 404 - 判断用户请求是否为
/或index.html首页 - 判断用户请求的是否为
/ about.html关于首页 - 设置
Content-Type响应头,防止中文乱码。 - 使用
res.end()把内容相应给客户端。
2. 动态响应内容
const http = require('http')
const server = http.createServer()
server.on('request', function (req, res) {
const url = req.url
let content = '<h1>404 not found!</h1>'
if (url === '/' || url === '/index.html') {
content = '<h1>首页</h1>'
} else if (url === '/about.html') {
content = '<h1>关于页面</h1>'
}
res.setHeader('Content-Type', 'text/html; charset = utf-8')
res.end(content)
})
server.listen(80, () => {
console.log('server running at http://127.0.0.1');
})
实现clock时钟的web服务器
- 核心思路
把文件的实际存放路径,作为每个资源的请求url地址。
- 服务器充当的角色就是一个字符串的搬运工
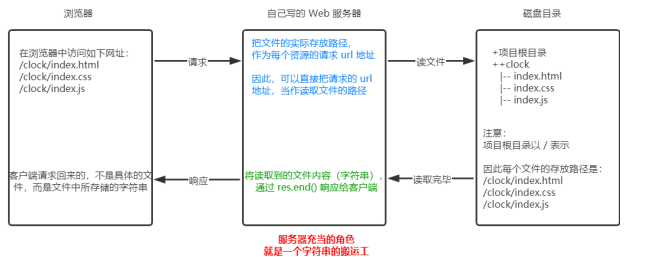
- 实现步骤
- 导入需要的模块
- 创建基本的web服务器
- 将资源的请求url地址映射为文件的存放路径
- 读取文件内容并响应给客户端
- 优化资源请求路径
- 导入需要模块
- http模块
- fs文件模块
- path模块
- 创建基本的服务器
- 将资源请求的url地址映射为文件的存放路径
- 读取文件的内容响应给客户端
- 优化资源请求,将访问路径直接定位到主页面
根据不同的url响应不同的url页面
const http = require('http')
const server = http.createServer()
server.on('request', (req, res) => {
console.log(req.url);
//设置当前已经有的响应
var arr = ["/main", "/login"]
//查看是否包含,如果包含返回200,否则是404,状态码出现变化。
var statusCode = arr.includes(req.url) ? 200 : 404
res.writeHeader(statusCode, { "Content-Type": "text/html; charset=utf-8" })
switch (req.url) {
case "/login": res.write("<h1>这是Login页面</h1>"); break;
case "/main": res.write("<h1>这是Main页面</h1>"); break;
default:
res.write("<h1>404 not found</h1>"); break;
}
res.end()
})
server.listen('8080', () => {
console.log('server running at http://127.0.0.1:8080');
})
/**
* /login 登陆页面
* /main main页面
* /其他 404页面
* 1. 获取url地址
* 2. 判断用户请求,响应对应内容
* 3. 设置相应头信息,防止中文乱码
* 4. 响应给客户端
*/
模块化
什么是模块化
模块化是指解决一个复杂问题时,自顶向下逐层把系统划分成若干模块的过程。对于整个系统来说,模块是可组合、分解和更换的单元。
模块化的好处
- 提高了代码的
复用性 - 提高了代码的
可维护性 - 可以实现
按需加载 - 代码低耦合,功能模块直接,不相互影响
模块化规范
例如:
- 使用啥样的语法格式来
引用模块。 - 在模块中使用啥样的语法格式向外暴漏成员。
模块化思想解决问题
- 可维护性:每个模块都是单独定义的,维护只在本模块中。
- 命名冲突:每个模块都有其各自的作用域,所以每个模块中就算定义了相同命名的变量,但也不相互冲突。
- 文件依赖:一个功能可以依赖多个文件。
Node.js中的模块化
Node.js中模块的分类
内置模块
内置模块是由node.js官方提供的,例如fs,path,http等。
自定义模块
用户创建的每个.js文件,都是自定义模块。
第三方模块
由第三方发出来的模块,并非官方提供的内置模块,也不是用户创建的自定义模块,使用前需要下载。
//1.加载内部模块不需要指定路径
var http = require('http')
//2. 加载用户的自定义模块
var sum = require('./b')
//3. 加载第三方模块
var md5 = require('md5')
暴露模块
在模块中通过exports和module.exports暴露,暴漏出去的时候的数据数据类型是对象。
function test() {
console.log('aaa---test');
}
function demo(str) {
console.log(str);
}
exports.demo = demo;
exports.test = test;
model.exports = {
test: test,
demo: demo
}
提示
exports可以暴露多次,而module.exports只能暴露一次,所以一般使用
大括号,对象的格式。exports和model.exports都是暴露。但最终还是得以model.exports暴漏的为准。在另外一个模块中使用时,就必须先加载,后使用
对象.方法(参数/无参数)的方式去使用。
加载模块
require()方法,可以加载需要的模块。
注意:
使用require( )方法加载其他模块时,会执行被加载模块中的代码。
在使用 require 加载用户自定义模块期间,可以省略 .js 的后缀名
- 定义自定义模块
06.m1.js
// 当前这个文件,就是一个用户自定义模块
console.log('加载了06这个用户自定义模块')
- 定义测试模块07.test.js
// 注意:在使用 require 加载用户自定义模块期间,
// 可以省略 .js 的后缀名
const m1 = require('./06.m1.js')
console.log(m1)
- 执行终端输入
PS E:\VScodeWorkSpace\node.js\第二天> nodemon .\07.test.js
- 返回结果
[nodemon] 2.0.15
[nodemon] to restart at any time, enter `rs`
[nodemon] watching path(s): *.*
[nodemon] watching extensions: js,mjs,json
[nodemon] starting `node .\07.test.js`
加载了06这个用户自定义模块
{}
[nodemon] clean exit - waiting for changes before restart
注意:
返回了一个空对象,这和下面的模块作用域有关系。
Node.js中的模块作用域
- 什么是
模块作用域
和函数作用域类似,在自定义模块中定义的变量、方法等成员,只能在当前模块内被访问,这种模块级别的访问限制,叫做模块作用域。 - 模块作用域的
好处
防止了全局变量污染的问题
- 定义自定义模块
08模块作用域
const username = '张三'
function sayHello() {
console.log('大家好,我是' + username)
}
sayHello()
- 定义自定义模块
09.test.js
const custom = require('./08.模块作用域')
console.log(custom)
- 终端
PS E:\VScodeWorkSpace\node.js\第二天> nodemon .\09.test.js
[nodemon] 2.0.15
[nodemon] to restart at any time, enter `rs`
[nodemon] watching path(s): *.*
[nodemon] watching extensions: js,mjs,json
[nodemon] starting `node .\09.test.js`
大家好,我是张三
{}
[nodemon] clean exit - waiting for changes before restart
向外共享模块作用域中的成员
-
module对象
在每个 .js 自定义模块中都有一个 module 对象,它里面存储了和当前模块有关的信息,打印如下:

-
module.exports对象
在自定义模块中,可以使用 module.exports 对象,将模块内的成员共享出去,供外界使用。
外界用require()方法导入自定义模块时,得到的就是 module.exports 所指向的对象。
注意:使用 require() 方法导入模块时,导入的结果,
永远以 module.exports 指向的对象为准。
- 自定义组件
11.自定义模块
// 在一个自定义模块中,默认情况下, module.exports = {}
const age = 20
// 向 module.exports 对象上挂载 username 属性
module.exports.username = 'zs'
// 向 module.exports 对象上挂载 sayHello 方法
module.exports.sayHello = function() {
console.log('Hello!')
}
module.exports.age = age
// 让 module.exports 指向一个全新的对象
module.exports = {
nickname: '小黑',
sayHi() {
console.log('Hi!')
}
}
12.test.js
// 在外界使用 require 导入一个自定义模块的时候,得到的成员,
// 就是 那个模块中,通过 module.exports 指向的那个对象
const m = require('./11.自定义模块')
console.log(m)
- 终端输入
PS E:\VScodeWorkSpace\node.js\第二天> node .\12.test.js
{ nickname: '小黑', sayHi: [Function: sayHi] }
- 注释exprots指向的全新对象
// 在一个自定义模块中,默认情况下, module.exports = {}
const age = 20
// 向 module.exports 对象上挂载 username 属性
module.exports.username = 'zs'
// 向 module.exports 对象上挂载 sayHello 方法
module.exports.sayHello = function () {
console.log('Hello!')
}
module.exports.age = age
- 终端输出
PS E:\VScodeWorkSpace\node.js\第二天> node .\12.test.js
{ username: 'zs', sayHello: [Function (anonymous)], age: 20 }
- 总结
新指向的会覆盖旧指向的module.explort对象。
exports对象
由于 module.exports 单词写起来比较复杂,为了简化向外共享成员的代码,Node 提供了 exports 对象。默认情况下,exports 和 module.exports 指向同一个对象。最终共享的结果,还是以 module.exports 指向的对象为准。
exports和module.exports的使用误区
时刻谨记,require() 模块时,得到的永远是 module.exports 指向的对象
注意:
为了防止混乱,建议大家不要在同一个模块中同时使用 exports 和 module.exports
Node.js中的模块化规范
Node.js 遵循了 CommonJS 模块化规范,CommonJS 规定了模块的特性和各模块之间如何相互依赖。
CommonJS规定:
- 每个module 变量是一个对象,它的 exports 属性(即 module.exports)是对外的接口。
- module 变量是一个对象,它的 exports 属性(即 module.exports)是对外的接口。
- 加载某个模块,其实是加载该模块的 module.exports 属性。require() 方法用于加载模块。
npm与包
什么是包
Node.js中的第三方模块又叫做包。
包的来源
不同于 Node.js 中的内置模块与自定义模块,包是由第三方个人或团队开发出来的,免费供所有人使用。
注意:
Node.js 中的包都是免费以及开源的,不需要付费即可免费下载使用。
为啥需要包
- 由于 Node.js 的内置模块仅提供了一些底层的 API,导致在基于内置模块进行项目开发的时,效率很低。
- 包是基于内置模块封装出来的,提供了更高级、更方便的 API,极大的提高了开发效率。
- 包和内置模块之间的关系,类似于 jQuery 和 浏览器内置 API 之间的关系。
下载包
npm的相关命令
npm initnpm install 包名npm i 包名下载包,放到node_modules文件夹里npm i 包名 --savenpm i 包名 -S(开发环境)npm i 包名 -- save-devnpm i 包名 -D(生产环境中)npm list列举当前目录下安装的包npm i 包名@1.0.1安装指定版本npm i 包名 -g安装全局包npm uninstall 包名卸载包
初次装包后多了哪些文件
初次装包完成后,在项目文件夹下多一个叫做 node_modules 的文件夹和package-lock.json的配置文件。
其中:
node_modules 文件夹用来存放所有已安装到项目中的包。require() 导入第三方包时,就是从这个目录中查找并加载包。
package-lock.json 配置文件用来记录 node_modules 目录下的每一个包的下载信息,正如其名lock-将版本锁住,这样程序到了其他程序员的手里下载相关依赖包的时候,版本都不会再变。
注意:
程序员不要手动修改 node_modules 或 package-lock.json 文件中的任何代码,npm 包管理工具会自动维护它们。
安装指定版本的包
默认情况下,使用 npm install 命令安装包的时候,会自动安装最新版本的包。如果需要安装指定版本的包,可以在包名之后,通过@ 符号指定具体的版本。
包的语义化版本规范
包的版本号是以“点分十进制”形式进行定义的,总共有三位数字,例如 2.24.0
其中每一位数字所代表的的含义如下:
第1位数字:大版本
第2位数字:功能版本
第3位数字:Bug修复版本
注意:
版本号提升的规则:只要前面的版本号增长了,则后面的版本号归零。
包配置管理文件
npm 规定,在项目根目录中,必须提供一个叫做 package.json 的包管理配置文件。用来记录与项目有关的一些配置
信息。例如:
- 项目的名称、版本号、描述等.
- 项目中都用到了哪些包
- 哪些包只在
开发期间会用到 - 那些包在
开发和部署时都需要用到
多人协作
遇到问题:第三方包的体积过大,不利于团队成员之间共享项目源代码。
解决方案:共享时剔除node_modules
使用package.json配置文件记录
在项目根目录中,创建一个叫做 package.json 的配置文件,即可用来记录项目中安装了哪些包。从而方便剔除node_modules 目录之后,在团队成员之间共享项目的源代码。
注意:
今后在项目开发中,一定要把 node_modules 文件夹,添加到 .gitignore 忽略文件中
快速创建package.json
npm包管理工具提供了一个快捷命令,可以在执行命令时所处的目录中,快速创建package.json这个包管理配置文件:
npm init -y
注意:
- 上述命令
只能在英文的目录下成功运行!所以,项目文件夹的名称一定要使用英文命名,不要使用中文,不能出现空格。- 运行 npm install 命令安装包的时候,npm 包管理工具会自动把
包的名称和版本号,记录到 package.json 中。
dependencies节点
package.json 文件中,有一个 dependencies 节点,专门用来记录您使用 npm install 命令安装了哪些包
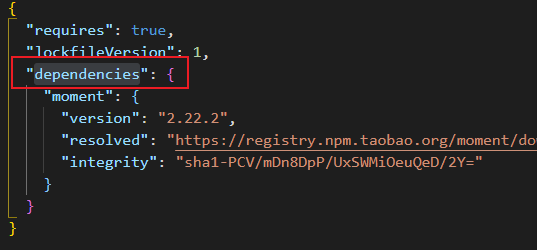
一次性安装所有的包
当我们拿到一个剔除了 node_modules 的项目之后,需要先把所有的包下载到项目中,才能将项目运行起来。
可以运行 npm install 命令(或 npm i)一次性安装所有的依赖包。

npm i
卸载包
可以运行 npm uninstall 命令,来卸载指定的包:
npm uninstall moment //卸载moment包
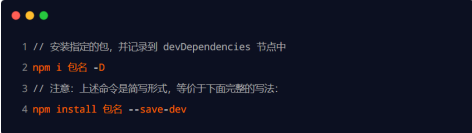
devDependencies 节点
- 如果某些包
只在项目开发阶段会用到,在项目上线之后不会用到,则建议把这些包记录到 devDependencies 节点中。 - 与之对应的,如果某些包在
开发和项目上线之后都需要用到,则建议把这些包记录到 dependencies 节点中。
可以使用如下的命令,将包记录到 devDependencies 节点中:
切换npm的下包镜像源
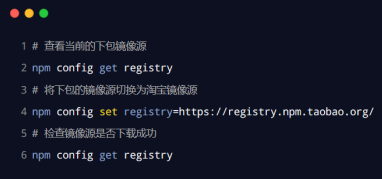
解决下包速度慢的问题
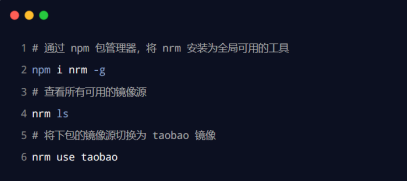
nrm
为了更方便的切换下包的镜像源,我们可以安装 nrm 这个小工具,利用 nrm 提供的终端命令,可以快速查看和切换下包的镜像源。
包的分类
使用 npm 包管理工具下载的包,共分为两大类,分别是:
项目包
那些被安装到项目的 node_modules 目录中的包,都是项目包。
项目包又分为两类,分别是:
开发依赖包(被记录到 devDependencies 节点中的包,只在开发期间会用到)核心依赖包(被记录到 dependencies 节点中的包,在开发期间和项目上线之后都会用到)

全局包
在执行 npm install 命令时,如果提供了 -g 参数,则会把包安装为全局包。
全局包会被安装到 C:\Users\用户目录\AppData\Roaming\npm\node_modules(默认,配置了就另说) 目录下。

注意:
- 只有
工具性质的包,才有全局安装的必要性。因为它们提供了好用的终端命令。- 判断某个包是否需要全局安装后才能使用,可以
参考官方提供的使用说明即可。
内置模块的加载机制
内置模块是由 Node.js 官方提供的模块,内置模块的加载优先级最高
例如:require(‘fs’) 始终返回内置的 fs 模块,即使在 node_modules 目录下有名字相同的fs模块,但引入的仍是node.js的内置模块。
自定义模块的加载机制
使用 require() 加载自定义模块时,必须指定以 ./ 或 ../ 开头的路径标识符。在加载自定义模块时,如果没有指定 ./ 或 …/ 这样的路径标识符,则 node 会把它当作内置模块或第三方模块进行加载。
同时,在使用 require() 导入自定义模块时,如果省略了文件的扩展名,则 Node.js 会按顺序分别尝试加载以下的文件:
- 按照确切的文件名进行加载
- 补全
.js扩展名进行加载 - 补全
.json扩展名进行加载 - 补全
.node扩展名进行加载 - 加载失败,终端报错
第三方模块加载机制
如果传递给 require() 的模块标识符不是一个内置模块,也没有以 ‘./’ 或 ‘…/’ 开头,则 Node.js 会从当前模块的父目录开始,尝试从 /node_modules 文件夹中加载第三方模块。
如果没有找到对应的第三方模块,则移动到再上一层父目录中,进行加载,直到文件系统的根目·录。
目录作为模块
当把目录作为模块标识符,传递给 require() 进行加载的时候,有三种加载方式:
- 在被加载的目录下查找一个叫做 package.json 的文件,并寻找 main 属性,作为 require() 加载的入口。
- 如果目录里没有 package.json 文件,或者 main 入口不存在或无法解析,则 Node.js 将会试图加载目录下的 index.js 文件。
- 如果以上两步都失败了,则 Node.js 会在终端打印错误消息,报告模块的缺失:Error: Cannot find module 'xxx’
格式化时间的高级做法
- 使用 npm 包管理工具,在项目中安装格式化时间的包
moment - 使用require()导入格式化时间的包
- 参考moment的官方API文档时间进行格式化
// 1. 导入需要的包
// 注意:导入的名称,就是装包时候的名称
const moment = require('moment')
const dt = moment().format('YYYY-MM-DD HH:mm:ss')
console.log(dt)
注意:
在使用前必须先安装moment模块。
原生路由
步骤
- 在静态资源文件夹中定义三个html文件,来实现页面的跳转
- 定义一个router.js文件,专门负责页面的跳转。
- 定义一个server.js文件,负责服务器的搭建。
源码
router.js
const fs = require("fs")
function render(res, path) {
res.setHeader('Content-Type', 'text/html; charset=utf-8')
res.write(fs.readFileSync(path))
}
var route = {
'/login': (res) => {
render(res, "./static/login.html")
},
'/index': (res) => {
render(res, "./static/index.html")
},
'/404': (res) => {
// render(res, "./static/login.html")
res.setHeader('Content-Type', 'text/html; charset=utf-8')
res.write(fs.readFileSync("./static/404.html"))
}
}
module.exports = route;
提示
router最后是以对象的格式进行封装的,类似Vue的路由,使用
render函数对代码进行封装,减少冗余。
server.js
const http = require("http");
const url = require("url")
// 这里引入了上面暴露的route模块
const router = require("./router")
// {
// '/login': [Function: /login],
// '/index': [Function: /index],
// '/404': [Function: /404]
// }
const server = http.createServer((req, res) => {
const pathname = url.parse(req.url).pathname;
//使用try catch来封装,保证出现错误时,可以跳转到404页面
try {
router[pathname](res)
} catch (e) {
router['/404'](res)
}
// console.log(router.route[pathname](res)); 错误语法
// router.route[pathname](res);
//根据不同的路径,响应不同的页面
res.end();
});
server.listen(3000, () => {
console.log('server is running at http://127.0.0.1:3000');
})
注意
- 这里重点注意一下router是对象类型的,得使用
router[pathname](res)才能访问到对象的方法,并将参数res传给函数- 还有就是
JavaScript的错误处理机制,这里使用了try...catch来处理url路径出错的情况,并使得程序出错时,可以跳转到404页面。
还剩下3个页面,由于结构简单,也没有展示的必要了。
JSON
一、概念:
JSON(
JavaScriptObjectNotation, JS对象表示法)简单来讲,JSON 就是 Javascript 对象和数组的字符串表示法,因此,JSON 的本质是字符串。
作用:JSON 是一种轻量级的文本数据交换格式,在作用上类似于 XML,专门用于存储和传输数据,但是 JSON 比 XML 更小、更快、更易解析。
现状:JSON 是在 2001 年开始被推广和使用的数据格式,到现今为止,JSON 已经成为了主流的数据交换格式。
二、JSON的两种结构
JSON 就是用字符串来表示 Javascript 的对象和数组。所以,JSON 中包含对象和数组两种结构,通过这两种结构的相互嵌套,可以表示各种复杂的数据结构。
-
对象结构:对象结构在 JSON 中表示为 { } 括起来的内容。数据结构为 { key: value, key: value, … } 的键值对结构。其中,key 必须是使用英文的双引号包裹的字符串,value 的数据类型可以是数字、字符串、布尔值、null、数组、对象6种类型。
{ "name": "zs", "age": 20, "gender": "男", "hobby": ["吃饭", "睡觉"] } -
数组结构:数组结构在 JSON 中表示为 [ ] 括起来的内容。数据结构为 [ “java”, “javascript”, 30, true … ] 。数组中数据的类型可以是数字、字符串、布尔值、null、数组、对象6种类型。
[ 100, 200, 300 ] [ true, false, null ] [ { "name": "zs", "age": 20}, { "name": "ls", "age": 30} ] [ [ "aaa", "bbb", "ccc" ], [ 1, 2, 3 ] ]
三、JSON语法的注意事项
- 属性名必须使用双引号包裹
- 字符串类型的值必须使用双引号包裹
- JSON 中不允许使用单引号表示字符串
- JSON 中不能写注释
- JSON 的最外层必须是对象或数组格式
- 不能使用 undefined 或函数作为 JSON 的值
- JSON 的作用:在计算机与网络之间存储和传输数据
- JSON 的本质:用字符串来表示 Javascript 对象数据或数组数据
四、JSON和JS对象的关系
JSON 是 JS 对象的字符串表示法,它使用文本表示一个 JS 对象的信息,本质是一个字符串。
//这是一个对象
var obj = {a: 'Hello', b: 'World'}
//这是一个 JSON 字符串,本质是一个字符串
var json = '{"a": "Hello", "b": "World"}'
五、JSON和JS对象的互转
- 要实现从 JSON 字符串转换为 JS 对象,使用 JSON.parse() 方法
- 要实现从 JS 对象转换为 JSON 字符串,使用 JSON.stringify() 方法
Ajax
概念
Ajax全称为(Asynchronous javaScript And XML),是异步的javaScript和XML。使用Ajax向服务器发送异步请求,最大的优势就是不用刷新页面就可以获取数据.
Ajax Web应用模型

XML
- XML指可拓展标记语言,HTML超文本标记语言
- XML被设计用来传输和存储数据。
- XML和HTML类似,不同的是HTML都是预定义的标签,而XML没有预定义标签,全部都是自定义的标签,用来表示一些数据。
特点
优点
- 无刷新页面就可以与服务器进行通信
- 允许你根据用户事件来更新部分页面的内容
缺点
- 没有浏览历史,不能回退。
- 存在跨域问题。 同源策略:协议,域名,端口号必须一致。
- SEO不友好。
实现AJAX的步骤
1、创建XML HttpRequest 对象,即创建一个异步调用对象。
2、创建一个新的HTTP 请求,并指定该HTTP 请求的方法,URL及验证信息
3、设置响应HTTP请求状态变化的函数。
4、发送HTTP 请求。
5、获取异步调用返回的数据。
6、使用JavaScript和DOM 实现局部刷新
get方式
- 创建XMLHttpRequest对象。
- 创建HTTP请求
XMLHttpRequest.open(method,URL,async,username,password)
提示
各个参数的解析
1、method 参数是用于请求的 HTTP 方法。值包括 GET 、POST、HEAD、PUT、DELETE(不区分大小写)
2、url 参数是请求的主体。大多数浏览器实施了一个同源安全策略,并且要求这个URL 与包含脚本的文本具有相同的主机名和端口
3、async 参数指示请求使用应该异步执行。如果这个参数为 false,代表请求是同步的,后续对 send() 的调用将阻塞,直到响应完全接受;如果这个参数是 true 或省略,请求是异步的,且通常需要一个 onreadystatechange 事件句柄。
4、username 和 password 参数是可选的,为 url 所需的授权提供认证资格。如果指定了,它们会覆盖 url 自己指定的任何资格。
- 设置响应HTTP请求状态变化的函数
创建完 HTTP 请求之后,就可以将HTTP请求发送给Web 服务器了,发送 HTTP 请求的目的是为了接受从服务器中返回的数据。从创建XMLHttpRequest对象,到发送数据、接收数据,一共会经历5种状态
拓展
1、未初始化状态。在创建完XMLHttpRequest对象时,该对象处于未初始化状态,此时XMLHttpRequest对象的readyState属性值为0。
2、初始化状态。在创建完XMLHttpRequest对象后使用open()方法创建了HTTP请求时,该对象处于初始化状态。此时XMLHttpRequest对象的readyState属性值为1。
3、发送数据状态。在初始化XMLHttpRequest对象后,使用send()方法发送数据时,该对象处于发送数据状态,此时XMLHttpRequest对象的readyState属性值为2。
4、接收数据状态。Web服务器接收完数据并进行处理完毕之后,向客户端传送返回的结果。此时,XMLHttpRequest对象处于接收数据状态,XMLHttpRequest对象的readyState属性值为3。
5、完成状态。XMLHttpRequest对象接收数据完毕后,进入完成状态,此时XMLHttpRequest对象的readyState属性值为4。此时接收完毕后的数据存入在客户端计算机的内存中,可以使用responseText属性或responseXml属性来获取数据。
- 设置获取服务器返回数据的语句
如果XMLHttpRequest对象的readyState属性值等于4,表示异步调用过程完毕。这个时候就可以获取数据了。异步调用过程完毕,并不代表异步调用成功了,如果要判断异步调用是否成功,还要判断 XMLHttpRequest 对象的status属性值,只有status === 200 ,才表示异步调用成功。
如果HTML文件不是在Web 服务器上运行,而是在本地运行,则 xmlHttpRequest.status 的返回值为 0
- 发送HTTP请求
XMLHttpRequest.send(data)
// 其中data是个可选参数,如果请求的数据不需要参数,即可以使用null来替代。
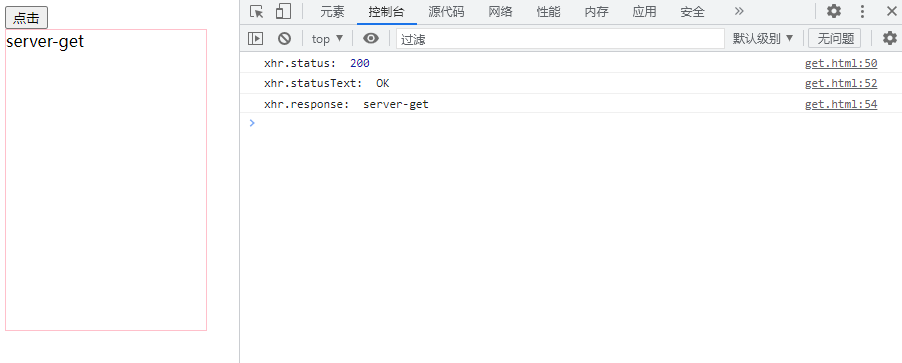
小试牛刀(案例)
//上面代码是定义了一个按钮,一个显示区域,并省略了获取元素的过程。从给按钮绑定监听事件开始。
btn.onclick = () => {
//1. 创建对象
var xhr = new XMLHttpRequest();
//2. 初始化 请求类型 请求地址
xhr.open("GET", "http://127.0.0.1:3000/server");
//3. 发送请求
xhr.send();
//4. 绑定事件进行监听,处理服务端返回的结果
//readystate : xhr身上的一个属性,记录客户端向服务器发送请求的状态
//0, 1 ,2, 3, 4
xhr.onreadystatechange = () => {
//服务器全部返回结果
if (xhr.readyState == 4) {
//判断响应的状态码 xhr.status
if (xhr.status == 200) {
//响应报文 行,头,体
console.log('xhr.status: ', xhr.status); //状态码
console.log('xhr.statusText: ', xhr.statusText); //状态描述
console.log('xhr.response: ', xhr.response); //响应体
div.innerHTML = xhr.response //将响应信息显示在输入框中
}
}
}
}
但要注意跨域问题,在入口文件index.js中设置header。
//应用级别的中间件
app.get("/server", (req, res) => {
//设置相应头,允许跨域访问
res.setHeader("Access-Control-Allow-Origin", "*")
res.send("server")
})
注意
不同浏览器创建XMLHttpRequest对象的方式是不同的
- 兼容性解决办法
var xmlHttpRequest ; // 创建一个变量,用于存放 XMLHttpRequest 对象 function createXMLHttpRequest() { if(window.ActiveXObject()){ // 判断是否是IE浏览器(IE也退休了) xmlHttpRequest = new ActiveXObject("Microsoft.XMLHTTP") } else if(window.XMLHttpRequest){ // 判断是否是 Netscape 或者其它 支持 XMLHttpRequest 组件的浏览器 xmlHttpRequest = new XMLHttpRequest() } } createXMLHttpRequest() // 调用创建对象的方法
post方式
//上面代码是定义了一个按钮,一个显示区域(没用上),并省略了获取元素的过程。从给按钮绑定监听事件开始。
btn.onmouseenter = function () {
var xhr = new XMLHttpRequest();
xhr.open("POST", "http://127.0.0.1:3000/server")
xhr.setRequestHeader("Content-Type", "application/x-www-form-urlencoded") //客户端告诉服务器实际发送的数据类型
//3.发送
xhr.send("username=zs&password=123456")
//4.监听
xhr.onreadystatechange = function () {
//当服务器传回整个数据
if (xhr.readyState == 4) {
//服务器响应成功
if (xhr.status == 200) {
//响应体
var res = JSON.parse(xhr.response)
console.log(res.code);
console.log('xhr.response: ', xhr.response);
}
}
}
}
同样需要在入口文件index.js中设置header来解决跨域问题,并返回一个参数data。
app.post("/server", (req, res) => {
console.log(req.body); //undefined
res.setHeader("Access-Control-Allow-Origin", "*")
var data = {
code: 1
}
res.send(JSON.stringify(data))
})

Ajax(Jquery)
<body>
<button id="get">get方式</button>
<button id="post">post方式</button>
<button id="all">all方式</button>
</body>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.js"></script>
<script>
// jquery是js的类库
// var div = document.querySelector("div");
// console.log(div);
// console.log($("div"));
$("#get").click(function () {
//路径,数据,成功以后返回数据
$.get("http://127.0.0.1:3000/server", { username: "zs" }, function (res) {
console.log(res);
})
})
//jquery中的post
$("#post").click(function () {
$.post("http://127.0.0.1:3000/server", { password: 123456 }, function (res) {
console.log();
//1. 手动转换 JSON.parse(res)
//2. 自动转换 最后一个参数添加'json'
}, 'json')
})
//jquery中的ajax
$("#all").click(function () {
$.ajax({
//请求地址
url: "http://127.0.0.1:3000/server",
// 请求方式
type: "post",
//数据
data: { username: "zs" },
dataType: "json",
//成功时执行回调函数
success: function (res) {
console.log(res);
//手动转换
// console.log(JSON.parse(res));
}
})
})
</script>
提示
ajax的使用可以到官方文档去看
Express
Express简介
Express是基于内置的http模块进一步封装出来的,能极大提高开发效率,类似于浏览器中 Web API 和 jQuery 的关系。后者是基于前者进一步封装出来的。
作用
对于前端程序员来说,最常见的两种服务器,分别是:
- Web 网站服务器:专门对外提供 Web 网页资源的服务器。
- API接口服务器:专门对内部提供Api的服务器。
使用 Express,我们可以方便、快速的创建 Web 网站的服务器或 API 接口的服务器
安装
npm i express@4.17.1
安装指定版本的express
创建基本的web服务器
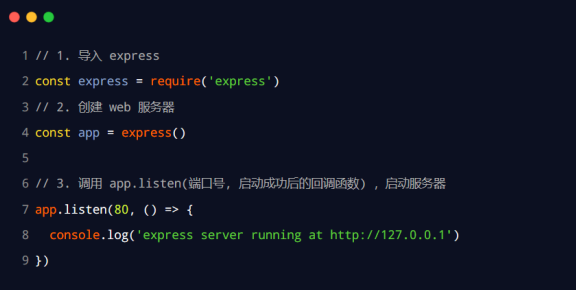
//1. 导入express
const express = require('express')
//2. 创建web服务器
const app = express()
//3.调用app.listen,启动服务器
app.listen(80, () => {
console.log('express server running at http://127.0.0.1');
})
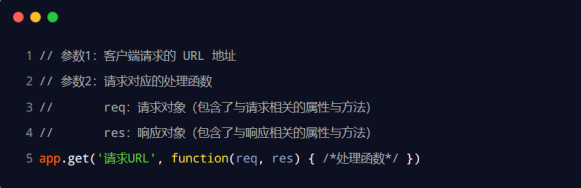
监听GET请求
通过 app.get() 方法,可以监听客户端的 GET 请求,具体的语法格式如下:
app.get('/liyu', (req, res) => {
//调用express提供的res.send方法向客户端提供一个json对象
res.send({ name: 'xz', age: 36, gender: '男' })
})
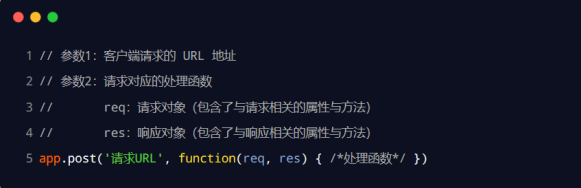
监听POST请求
通过 app.post() 方法,可以监听客户端的 POST 请求,具体的语法格式如下:
app.post('/liyu', (req, res) => {
//调用express提供的res.send方法向客户端提供一个文本服务器
res.send('请求成功')
})
把内容响应给客户端
通过res.send()方法,可以把处理好的内容,发送给客户端:
app.get('/liyu', (req, res) => {
//调用express提供的res.send方法向客户端提供一个json对象
res.send({ name: 'xz', age: 36, gender: '男' })
})
获取 URL 中携带的查询参数
通过 req.query 对象,可以访问到客户端通过查询字符串的形式,发送到服务器的参数:
app.get('/', (req, res) => {
//通过req.query获取客户端发送过来的查询参数
console.log(req.query);
})

获取 URL 中的动态参数
通过 req.params 对象,可以访问到 URL 中,通过 : 匹配到的动态参数:
app.get('/liyu/:id', (req, res) => {
//req.params是动态匹配到的url参数,默认空对象
console.log(req.params);
res.send(req.params)
})
注意:这里的id是一个动态的参数
托管静态资源
- eexpress.static()
express 提供了一个非常好用的函数,叫做 express.static(),通过它,我们可以非常方便地创建一个静态资源服务器,例如,通过如下代码就可以将 public 目录下的图片、CSS 文件、JavaScript 文件对外开放访问了:
app.use(express.static('public'))
app.use(express.static('files'))
现在,你就可以访问 public 目录中的所有文件了:
http://localhost:3000/images/bg.jpg
注意:
Express 在指定的静态目录中查找文件,并对外提供资源的访问路径。因此,存放静态文件的目录名不会出现在 URL 中。
托管多个静态资源目录
如果要托管多个静态资源目录,请多次调用 express.static() 函数:
app.use(express.static('public'))
注意:
访问静态资源文件时,express.static() 函数会根据目录的添加顺序查找所需的文件。
挂载路径前缀
如果希望在托管的静态资源访问路径之前,挂载路径前缀,则可以使用如下的方式:
app.use('/files', express.static('./files'))
现在,访问files时,就必须加上/files才可以访问到.
http://localhost:3000/files/index.html
动态路由
动态识别参数。
例如:/list/1, /list/2
可以使用/list/:id来匹配所有的路径。
Express静态资源托管
原生实现
- 请求 /css/index.css
- 寻找文件:使用绝对路径。
path.join(dirname,/css/index.css)
- 如果没有这个文件
res.write(fs.readFIleSync() ),res.writeHead(404 ),res.end()
- 如果有
res.write(fs.readFIleSync() ),res.writeHead(200,{'Content-Type':'text\html;charset=utf-8'} ),res.end();
注意
3.4步,需要设置的响应头内容是不同的是,所以接下来要使用mime模块去自动解析文件后缀
- 处理文件内容
使用mime模块,使用path内置模块获取到扩展名,在用mime去处理
Express实现
为了提供诸如图像、CSS 文件和 JavaScript 文件之类的静态文件,请使用 Express 中的 express.static 内置中间件函数。
函数特征
express.static(root,[options])
例如,通过如下代码就可以将 public 目录下的图片、CSS 文件、JavaScript 文件对外开放访问了:
app.use(express.static('public'))
现在,你就可以访问 public 目录中的所有文件了:
http://localhost:3000/images/kitten.jpg
http://localhost:3000/css/style.css
http://localhost:3000/js/app.js
http://localhost:3000/images/bg.png
http://localhost:3000/hello.html
Express 在静态目录查找文件,因此,存放静态文件的目录名不会出现在 URL 中。
如果要使用多个静态资源目录,请多次调用 express.static 中间件函数:
app.use(express.static('public'))
app.use(express.static('files'))
虚拟路径(没有意义)
访问静态资源文件时,express.static 中间件函数会根据目录的添加顺序查找所需的文件。
app.use('/static', express.static('public'))
现在,你就可以通过带有 /static 前缀地址来访问 public 目录中的文件了。
http://localhost:3000/static/images/kitten.jpg
http://localhost:3000/static/css/style.css
http://localhost:3000/static/js/app.js
http://localhost:3000/static/images/bg.png
http://localhost:3000/static/hello.html
然而,你提供给express.static函数的路径是相对于你启动node进程的目录的。如果您从另一个目录运行 express 应用程序,使用您要服务的目录的绝对路径会更安全:
const path = require('path')
app.use('/static', express.static(path.join(__dirname, 'public')))
Express路由
路由是什么
广义上来讲,路由就是映射关系。

Express 中的路由
在 Express 中,路由指的是客户端的请求与服务器处理函数之间的映射关系。
Express 中的路由分 3 部分组成,分别是请求的类型、请求的 URL 地址、处理函数,格式如下:
app.METHOD(PATH, HANDLER)
| 名称 | 描述 |
|---|---|
| app | app 是一个 express 实例 |
| METHOD | METHOD用于指定要匹配的HTTP请求方式 |
| PATH | PATH是服务器端的路径 |
| HANDLER | 是当路由匹配时需要执行的处理程序(回调函数) |
路由路径和请求方法一起定义了请求的端点,它可以是字符串,字符串模式以及正则表达式。
app.get('/', function (req, res) {
res.send('root')
})
app.get('/about', function (req, res) {
res.send('about')
})
app.get('/random.text', function (req, res) {
res.send('random.text')
})
使用字符串模式的路由路径示例:
app.get('/ab?cd', function (req, res) {
res.send('ab?cd') //abcd ,acd
})
app.get('/ab/:id', function (req, res) {
res.send('ab/:id')
})
app.get('/ab+cd', function (req, res) {
res.send('ab+cd') //b可以一次或者多次的重复
})
app.get('/ab*cd', function (req, res) {
res.send('ab*cd') //在ab,cd之间随意写入任意字符
})
app.get('/ab(cd)?e', function (req, res) {
res.send('ab(cd)?e')
})
可以为请求处理提供多个回调函数,其行为类似中间件。
案例:中间件f1,f2
app.get('/example/b', function (req, res, next) {
console.log('the response will be sent by the next function ...')
next()
}, function (req, res) {
res.send('Hello from B!')
})
var cb0 = function (req, res, next) {
console.log('CB0')
next()
}
var cb1 = function (req, res, next) {
console.log('CB1')
next()
}
var cb2 = function (req, res) {
res.send('Hello from C!')
}
app.get('/example/c', [cb0, cb1, cb2])
var cb0 = function (req, res, next) {
console.log('CB0')
next()
}
var cb1 = function (req, res, next) {
console.log('CB1')
next()
}
app.get('/example/d', [cb0, cb1], function (req, res, next) {
console.log('the response will be sent by the next function ...')
next()
}, function (req, res) {
res.send('Hello from D!')
})
例子
//匹配GET请求,且请求URL为/
app.get('/',funcation(req,res){
res.send('hello World!')
})
// 匹配POST请求,且请求URL为/
app.post('/',funcation(req,res){
res.send('Got a POST request')
})
路由的匹配过程
每当一个请求到达服务器之后,需要先经过路由的匹配,只有匹配成功之后,才会调用对应的处理函数。
在匹配时,会按照路由的顺序进行匹配,如果请求类型和请求的 URL 同时匹配成功,则 Express 会将这次请求,转交给对应的 function 函数进行处理。
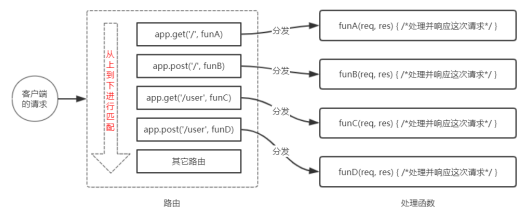
注意点:
- 按照定义的
先后顺序进行匹配请求类型和请求的url同时匹配成功才会调用对应的处理函数.
路由的使用
最简单的写法
在Express中使用路由最简单的方式,就是把路由挂载到 app 上,示例如下:
const express = require('express')
const app = express()
// 挂载路由
app.get('/', (req, res) => {
res.send('hello world.')
})
app.post('/', (req, res) => {
res.send('Post Request.')
})
app.listen(80, () => {
console.log('http://127.0.0.1')
})
模块化路由
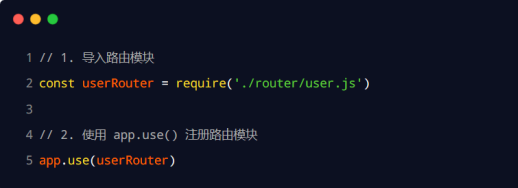
为了方便对路由进行模块化的管理,Express 不建议将路由直接挂载到 app 上,而是推荐将路由抽离为单独的模块。将路由抽离为单独模块的步骤如下:
- 创建路由模块对应的 .js 文件.
- 调用 express.Router() 函数创建路由对象
- 向路由对象上挂载具体的路由
- 使用 module.exports 向外共享路由对象
- 使用 app.use() 函数注册路由模块
- 创建路由模块
// 这是路由模块
// 1. 导入 express
const express = require('express')
// 2. 创建路由对象
const router = express.Router()
// 3. 挂载具体的路由
router.get('/user/list', (req, res) => {
res.send('Get user list.')
})
router.post('/user/add', (req, res) => {
res.send('Add new user.')
})
// 4. 向外导出路由对象
module.exports = router
- 注册路由模块
const express = require('express')
const app = express()
// app.use('/files', express.static('./files'))
// 1. 导入路由模块
const router = require('./03.router')
// 2. 注册路由模块
app.use('/api', router)
// 注意: app.use() 函数的作用,就是来注册全局中间件
app.listen(80, () => {
console.log('http://127.0.0.1')
})
为路由模块添加前缀
类似于托管静态资源时,为静态资源统一挂载访问前缀一样,路由模块添加前缀的方式也非常简单:
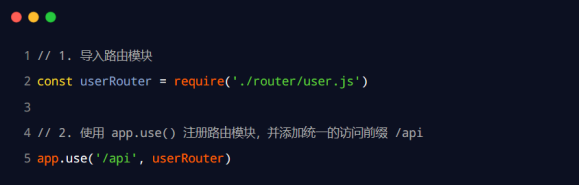
app.use('/api', router)
Express 中间件
什么是中间件
中间件(Middleware ),特指业务流程的中间处理环节.
现实生活中的例子
在处理污水的时候,一般都要经过三个处理环节,从而保证处理过后的废水,达到排放标准。
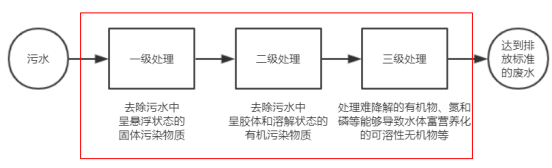
处理污水的这三个中间处理环节,就可以叫做中间件。
Express 中间件的调用流程
当一个请求到达 Express 的服务器之后,可以连续调用多个中间件,从而对这次请求进行预处理。
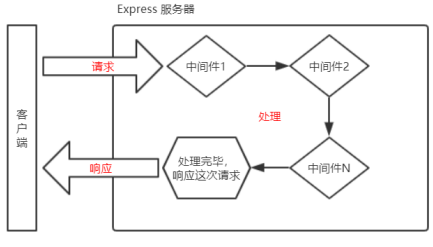
注意:上一个中间件的输出会作为下一个中间件的输入。
Express 中间件的格式
Express 的中间件,本质上就是一个 function 处理函数,Express 中间件的格式如下:

注意:
中间件函数的形参列表中,必须包含 next 参数。而路由处理函数中只包含 req 和 res。
next 函数的作用
next 函数是实现多个中间件连续调用的关键,它表示把流转关系转交给下一个中间件或路由。
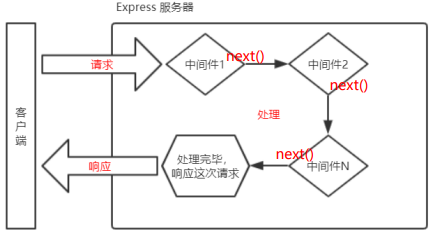
定义中间件函数
// 定义一个最简单的中间件函数
const mw = function (req, res, next) {
console.log('这是最简单的中间件函数')
// 把流转关系,转交给下一个中间件或路由
next()
}
// 将 mw 注册为全局生效的中间件
app.use(mw)
全局生效的中间件
客户端发起的任何请求,到达服务器之后,都会触发的中间件,叫做全局生效的中间件。
通过调用 app.use(中间件函数),即可定义一个全局生效的中间件,示例代码如下:
// 将 mw 注册为全局生效的中间件
app.use(mw)
定义全局中间件的简化形式
// 这是定义全局中间件的简化形式
app.use((req, res, next) => {
console.log('这是最简单的中间件函数')
next()
})
中间件的作用
多个中间件之间,共享一份req和res,基于这样的特性,我们可以在上游的中间件中,统一为req和res为对象添加自定义的属性和方法,供下游的中间件或路由进行使用。
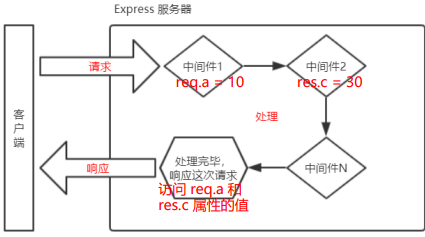
const express = require('express')
const app = express()
// 这是定义全局中间件的简化形式
app.use((req, res, next) => {
// 获取到请求到达服务器的时间
const time = Date.now()
// 为 req 对象,挂载自定义属性,从而把时间共享给后面的所有路由
req.startTime = time
next()
})
app.get('/', (req, res) => {
res.send('Home page.' + req.startTime)
})
app.get('/user', (req, res) => {
res.send('User page.' + req.startTime)
})
app.listen(80, () => {
console.log('http://127.0.0.1')
})
定义多个全局中间件
可以使用 app.use() 连续定义多个全局中间件。客户端请求到达服务器之后,会按照中间件定义的先后顺序依次进行调用,示例代码如下:
const express = require('express')
const app = express()
//定义第一个全局中间件
app.use((req, res, next) => {
console.log('调用了第一个全局中间件');
next()
})
app.use((req, res, next) => {
console.log('调用了第二个全局中间件');
next()
})
//定义一个路由
app.get('/user', (req, res) => {
res.send('User page!')
})
app.listen(80, () => {
console.log('http://127.0.0.1');
})
局部生效的中间件
不使用 app.use() 定义的中间件,叫做局部生效的中间件,示例代码如下:

// 导入 express 模块
const express = require('express')
// 创建 express 的服务器实例
const app = express()
//定义中间件函数
const mv1 = (req, res, next) => {
console.log('定义了一个局部生效的中间件');
next()
}
//创建路由
app.get('/', mv1, (req, res) => {
res.send('Home page!')
})
app.get('/user', (req, res) => {
res.send('User page!')
})
// 调用 app.listen 方法,指定端口号并启动web服务器
app.listen(80, function () {
console.log('Express server running at http://127.0.0.1')
})
注意:
中间件只会在添加的路由函数中起作用。
定义多个局部中间件
可以在路由中,通过如下两种等价的方式,使用多个局部中间件:
const mw1 = (req, res, next) => {
console.log('调用了第一个局部生效的中间件')
next()
}
const mw2 = (req, res, next) => {
console.log('调用了第二个局部生效的中间件')
next()
}
// 2. 创建路由,两种方式是“完全等价的”
app.get('/', [mw1, mw2], (req, res) => {
res.send('Home page.')
})
app.get('/admin', mw1, mw2, (req, res) => {
res.send('Admin page.')
})
//3.这个方式和上面的是“完全等价的”
app.get('/admin',[mw1],(req,res,next)=>{
console.log('调用了第二个局部生效的中间件')
next()
})
app.get('/user', (req, res) => {
res.send('User page.')
})
注意:在第二步创建路由时,两种方式是
完全等价的,按照自己的喜好进行设置。
了解中间件的5个注意事项
- 一定要在
路由之前注册中间件,这样才会对路由起效果 - 客户端发送过来的请求,
可以连续调用多个中间件进行处理 - 执行完中间件的业务代码之后,
不要忘记调用 next() 函数,把执行交给下一个路由。 - 为了
防止代码逻辑混乱,调用 next() 函数后不要再写额外的代码 - 连续调用多个中间件时,多个中间件之间,
共享req 和 res 对象
中间件的分类
Express 官方把常见的中间件用法,分成了 5 大类,分别是:
应用级别的中间件
通过 app.use() 或 app.get() 或 app.post() ,绑定到 app 实例上的中间件,叫做应用级别的中间件,代码示例如下:

拓展
凡是挂载到app身上的都是应用级别的中间件。
app.use():应用中的每个请求都可以执行其代码。
注意
执行有顺序要求,全局中间间一般放在代码首部
特定路由的应用级中间件
app.use("/center", (req, res, next) => {
console.log("验证身份呢")
next()
})
拓展
只能通过"/center"进行访问。
路由级别的中间件
绑定到 express.Router() 实例上的中间件,叫做路由级别的中间件。它的用法和应用级别中间件没有任何区别。只不过,应用级别中间件是绑定到 app 实例上,路由级别中间件绑定到 router 实例上,代码示例如下:
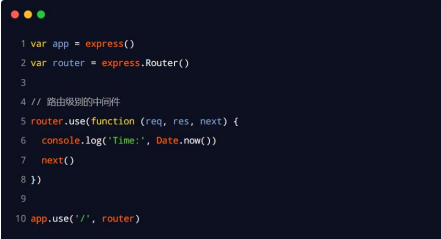
拓展
路由中间件:绑定到express.Router()上
router.Method();注册路由:并模块化。
错误级别的中间件
错误级别中间件的作用:专门用来捕获整个项目中发生的异常错误,从而防止项目异常崩溃的问题。
格式: 错误级别中间件的 function 处理函数中,
必须有 4 个形参,形参顺序从前到后,分别是 (err, req, res, next)。
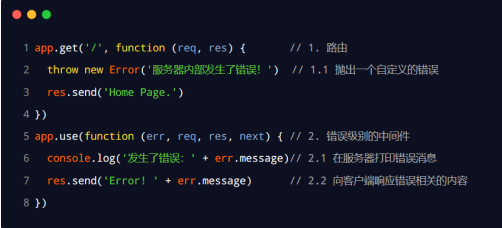
注意:
错误级别的中间件,必须注册在所有路由之后!
Express内置的中间件
自 Express 4.16.0 版本开始,Express 内置了 3 个常用的中间件,极大的提高了 Express 项目的开发效率和体验:
express.static快速托管静态资源的内置中间件,例如: HTML 文件、图片、CSS 样式等(无兼容性)express.json解析 JSON 格式的请求体数据(有兼容性,仅在 4.16.0+ 版本中可用)
拓展
application/json
由于JSON规范的流行,现在越来越多的开发者将application/json这个Content-Type作为响应头。用来告诉服务器端消息主体是序列化后的JSON字符串。除了低版本IE之外各大浏览器都原生支持JSON.stringify,服务端语言也都有处理JSON的函数,JSON能格式支持比键值对复杂得多的结构化数据,普通键值对中的值只能是字符串,而是用JSON,键值对可以重复嵌套。
//应用级别的中间件,获取post---json参数 app.use(express.json())
express.urlencoded解析 URL-encoded 格式的请求体数据(有兼容性,仅在 4.16.0+ 版本中可用)
拓展
application/x-www-form-urlencoded
浏览器原生form表单,如果不设置enctype属性,那么最终就会以application/x-www-form-urlencoded提交的数据按照key=val&key=val的方式进行编码,并且key和val都进行了URL转码。//应用级别中间件,获取post--form参数 app.use(express.urlencoded({ extended: false }))

// 导入 express 模块
const express = require('express')
// 创建 express 的服务器实例
const app = express()
// 注意:除了错误级别的中间件,其他的中间件,必须在路由之前进行配置
// 通过 express.json() 这个中间件,解析表单中的 JSON 格式的数据
app.use(express.json())
// 通过 express.urlencoded() 这个中间件,来解析 表单中的 url-encoded 格式的数据
app.use(express.urlencoded({ extended: false }))
app.post('/user', (req, res) => {
// 在服务器,可以使用 req.body 这个属性,来接收客户端发送过来的请求体数据
// 默认情况下,如果不配置解析表单数据的中间件,则 req.body 默认等于 undefined
console.log(req.body)
res.send('ok')
})
app.post('/book', (req, res) => {
// 在服务器端,可以通过 req,body 来获取 JSON 格式的表单数据和 url-encoded 格式的数据
console.log(req.body)
res.send('ok')
})
// 调用 app.listen 方法,指定端口号并启动web服务器
app.listen(80, function () {
console.log('Express server running at http://127.0.0.1')
})
第三方的中间件
非 Express 官方内置的,而是由第三方开发出来的中间件,叫做第三方中间件。在项目中,大家可以按需下载并配置第三方中间件,从而提高项目的开发效率。
例如:在 express@4.16.0 之前的版本中,经常使用 body-parser 这个第三方中间件,来解析请求体数据。使用步骤如下:
- 运行 npm install body-parser 安装中间件
- 使用 require 导入中间件
- 调用 app.use() 注册并使用中间件
注意:Express 内置的 express.urlencoded 中间件,就是基于 body-parser 这个第三方中间件进一步封装出来的
获取请求参数
- req.query 是一个可获取客户端get请求 查询字符串 转成的对象,默认为{}。
- req.body 包含在请求体中提交的数据键值对。默认情况下undefined,当使用解析中间件
express.json()、express.urlencoded()
项目案例
使用Express写一个登陆案例
- 先初始化项目,使用
npm init -y初始化出package.json文件 - 使用命令
npm i express安装express模块 - 在文件夹中创建
index.js(入口文件),router文件夹(用来存放路由),public(静态资源文件夹)
index.js
const express = require("express")
const apiRouter = require("./router/api")
const indexRouter = require("./router/index")
const loginRouter = require("./router/login")
const app = express()
app.use(express.static("public"))
app.use(express.static("static"))
app.use(express.urlencoded({ extended: false }))
//应用级别的中间件,获取post---json参数
app.use(express.json())
/**模块分类:
* 1. 内置模块:http,url,fs,path
* const http = require("http")
* 2. 自定义模块:自己写的单独的js文件
* 使用相对路径去引用
* const index = require("./router/index")
* 3. 第三方模块(包):第三方模块,npmjs网站去下载
* npm init -y (初始化package.json)
* npm install 包名 (下载)
* const md5 = require("md5")
*/
app.use('/index', indexRouter)
app.use('/login', loginRouter)
app.use('/api', apiRouter)
// app.get("/", (req, res) => {
// //接受数据
// //进行数据验证
// //连接数据库
// //判断
// //响应给客户端
// res.send("index")
// })
app.get("/api/nav/insert", (req, res) => {
res.send({
list: ["1111", "222", "333"]
})
})
app.listen('3000', () => {
console.log("server is running at http://127.0.0.1:3000");
})
- 在router中创建
login.js(后端接口)。
//路由中间件,模块化
const express = require("express")
const router = express.Router()
router.get("/", (req, res) => {
//get:req.query
console.log(req.query);
//解构赋值
const { username, password } = req.query
if (username == "admin" && password == "123456") {
res.send({
code: 1,
msg: "登陆成功"
})
} else {
res.send({
code: 0,
msg: "登陆失败"
})
}
})
router.post("/", (req, res) => {
//req.body
const { username, password } = req.body
if (username == "admin" && password == "123456") {
res.send({
code: 1,
msg: "登陆成功"
})
} else {
res.send({
code: 0,
msg: "登陆失败"
})
}
})
/**
* 1. 请求 /css/index.css
* 2. 寻找文件:绝对路径,path.join(__dirname,/css/index.css)
* 3. 没有:res.write(fs.readFIleSync() ),res.writeHead(404 ),res.end();
* 4. 有: res.write(fs.readFIleSync() ),res.writeHead(200,{'Content-Type':'text\html;charset=utf-8'} ),res.end();
* 5. 处理文件内容,mime类型,文件扩展名,
*/
//暴露出去
module.exports = router
注意:
- 在这里需要注意的就是对象的解构赋值,尽管自己知道ES6的语法,但一直没用过,这里需要记住,在以后的开发中经常使用。
- 一共写了两二级路由,一个是Post,一个是Get。Get相比于Post来说,一个数据是保存到query中的,另外一个是保存到body中。
- 最后再进行判断,并给前台返回一个值
- 创建login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div class="container">
login页面
<div>
<input type="text" id="un">
</div>
<div>
<input type="password" id="psd">
</div>
<div>
<button id="log">登陆</button>
<button id="logpost">登陆-post</button>
</div>
</div>
</body>
</html>
<script>
var username = document.querySelector("#un")
console.log('username: ', username);
var password = document.querySelector("#psd")
console.log('password: ', password);
var login = document.querySelector("#log")
console.log('login: ', login);
var loginpost = document.querySelector("#logpost")
//get请求
login.onclick = () => {
fetch(`/login?username=${username.value}&password=${password.value}`).then(res => res.json()).then(res => {
console.log(res);
//code=1,成功,跳转 index
//code=0,失败
if (res.code == 1) {
console.log(res.msg);
location.href = "/index.html"
} else {
console.log(res.msg);
}
})
}
//post请求
loginpost.onclick = function () {
fetch("/login", {
//不加引号会认为是变量
method: "post",
body: JSON.stringify({
username: username.value,
password: password.value
}),
headers: {
"Content-Type": "application/json"
}
}).then(res => res.json()).then(res => {
console.log(res);
})
}
</script>
注意:
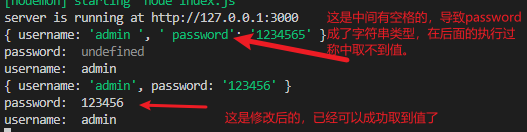
- 在使用get方式转值的时候,
&左右不能有空格。不然参数会是别错误。
- 两种方式,一中Get提交数据,另一种是Post提交数据,Post提交数据就要求提供header(请求头),data(保存数据):使用JSON.stringify将对象转换成字符串。
如果不配置内置的模块,是拿去不到body里的值的,会显示undefinedapp.use(express.urlencoded({ extended: false })) //应用级别的中间件,获取post---json参数 app.use(express.json())把这两行代码放到入口文件的首部(引入文件的下面)
- express需要配置静态资源,不然是访问不到页面的。
app.use(express.static("public")) app.use(express.static("static"))把这两行代码放到入口文件的首部(引入文件的下面)
- 引入静态文件时,注意文件的相对路径,不能有
.比如/static/index.css前面就不要加.不然会访问不到。
后端数据渲染
后端将数据传给前端,然后前端再渲染给后端
后端数据:
list: (3) [‘aaa’, ‘bbb’, ‘ccc’]
[[Prototype]]: Object
前端渲染后的数据:渲染后,在列表中展现出来
<script>
fetch("/index").then(res => res.json()).then(res => {
console.log(res.list);
// render(res.list)
})
function render(arr) {
console.log(arr);
方法一
var str = ""
arr.forEach((item, index) => {
str += `<li>${item}</li>`
// console.log(item);
})
// console.log(str);
var ul = document.querySelector("ul")
// console.log('ul: ', ul);
ul.innerHTML = str
方法二
var arrNew = []
arrNew = arr.map((item, index) => {
console.log('arrNew.join(""): ', arrNew.join(""));
return `<li>${item}</li>`
})
var str = ""
str = arrNew.join("")
console.log(arrNew);
var ul = document.querySelector("ul")
ul.innerHTML = str
// arr.map(callback) //映射
// arr.filter(callback) //过滤
方法三
str = ""
str = arr.map(v => `<li>${v}</li>`).join("")
console.log(str);
var ul = document.querySelector("ul")
ul.innerHTML = str
}
Express模板引擎
模板引擎的作用
模板引擎能够在应用程序中使用静态模板文件。在运行时,模板引擎将模板文件中的变量替换为实际的值,并将模板转换为发送给客户端的HTML文件。这种方法使得设计HTML页面变得更加容易
与express一起使用的一些流行模板引擎是Pug,Mustache和EJS。Express应用程序默认使用Pug,但他也支持其他几个。
需要在应用中进行如下设置才能让Express渲染模板引擎:
- view,放模板的文件目录,例如:
app.set('views','./views)。 - view engine,要使用的模板引擎。例如,要使用pug模板引擎:
app.set('view engine', 'pug')
在路由中渲染模板
在路由渲染模板并将渲染后的HTML字符串发送到客户端。
res.rander(view [, locals] [, callback])
- view:一个字符串,view是渲染的模板文件的文件路径。
- locals:一个对象,其属性定义视图的局部变量。
router.get("/", (req, res) => {
// res.send({ list: ['aaa', 'bbb', 'ccc'] })
res.render("list", { title: "新闻", list: ["aa", "bb", "cc"] })
})
ejs模板引擎的使用
安装ejs
npm i ejs
在express配置ejs模板引擎
使用ejs模板引擎
在入口文件中配置如下代码,配置Express使用ejs模板引擎
//配置模板引擎
app.set("views", path.join(__dirname, "./views")) //设置模板引擎的保存位置
app.set('view engine', 'ejs')
注意:
此时指定的模板目录为
views,且模板文件的后缀名为.ejs.而且在设置模板引擎的保存位置时,前面一定得是
views,否则会报View is not a constructor错误
设置模板后缀为html
在app.js中添加如下代码,配置Express使用ejs模板引擎。并指定模板后缀名为html。
app.set('views',path.join(__dirname,'views')); //设置模板存储位置
app.set('view engine','html');
app.engine('html',require('ejs').renderFile); //使用ejs模板引擎解析html
注意:此时指定的模板目录为
views,且模板文件的后缀名为.html。
ejs模板语法
<%= %> 输出标签
<%- %> 输出html标签(html会被浏览器解析)
<%# %> 注释标签
<% %> 流程控制标签(写的是if,else,for)
<%- include("header.html",{user:user})%> 导入公共的模板内容
<body>
<%- include("./haeder.html",{isShow:true})%>
这是list页面
<%=title%>
<ul>
<% for(var i=0;i<list.length;i++){ %>
<li>
<%=list[i]%>
</li>
<%} %>
</ul>
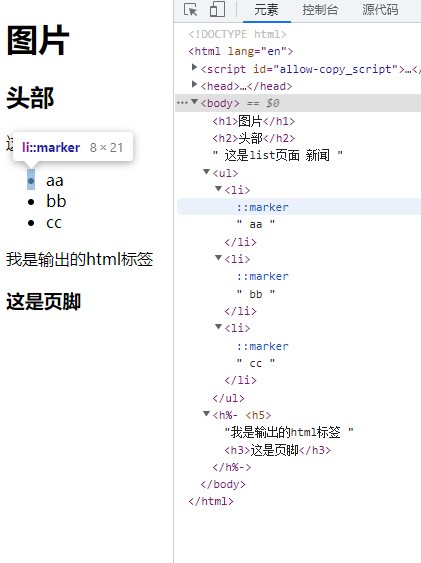
<h%- <h5>我是输出的html标签</h5>%>
<%# <h3>注释标签,不会显示在页面结构中</h3>%>
<%- include("./footer.html")%>
</body>
NunJucks模板引擎
模板引擎有很多,我之前就曾用过ejs,都是对页面进行渲染.接下来带大家简单体验一下Nunjucks.真别说,插值语法有点vue的那股味道了。
初试NunJucks模板引擎
- 先创建项目文件夹
nunjucksExprice - 初始化项目文件
npm init -y
- 引入NumJucks
提示
终端输入
npm install nunjucks
等待安装完成后,我们在安装express.js,来搭建一个服务器。
- 引入express.js
npm install express
- 创建视图文件夹
view - 在视图文件夹中创建
index.html文件 - 创建项目入口文件
index.js - 使用express创建服务器
const express = require("express")
const app = express()
app.listen('80', () => {
console.log('express is running at http://127.0.0.1/');
})
一个简单的服务器就创建好了。
- 在入口文件中引入
nunjucks,并使用node.js自带的path模块设置模板路径。
const express = require("express")
const nunjucks = require("nunjucks")
const path = require("path")
const app = express()
//设置模板存储位置
app.set("view", path.join(__dirname, "view"))
//设置模板引擎
nunjucks.configure("view", {
autoescape: true, //是否自动匹配
express: app
})
//设置视图引擎
app.set("view engine", "html")
//设置路由,进行页面渲染
app.get("/", (req, res) => {
res.render("index")
})
app.listen('80', () => {
console.log('express is running at http://127.0.0.1/');
})
上面的代码也可以这样写,这两种写法是等价的,唯一不同的区别在于一个设置了视图引擎,所以在渲染页面的时候
不用加.html后缀,一个没有设置,就需要加上.html后缀,否则模板引擎找不到页面。const express = require("express") const nunjucks = require("nunjucks") const path = require("path") const app = express() //设置模板存储位置 app.set("view", path.join(__dirname, "view")) //设置模板引擎 nunjucks.configure("view", { autoescape: true, //是否自动匹配 express: app }) app.get("/", (req, res) => { res.render("index.html") }) app.listen('80', () => { console.log('express is running at http://127.0.0.1/'); })
功能小试
接下来和我一起了解一下NumJucks的使用方法吧。
和ejs一样,NumJucks在渲染页面的时候也可以传值(key:value)的形式。
传递变量
我们创建一个变量str
str = 'Word'
app.get("/", (req, res) => {
res.render("index.html",{str})
})
str:ES6语法,键值一样写一个就行。
在页面中这样使用
{{str}}
循环遍历
我们创建一个数组
let list = ['橘子', '桃子', '西瓜']
app.get("/", (req, res) => {
res.render("index.html",{list})
})
在页面中这样使用
<ul>
{% for item in list%}
<li>{{item}}</li>
{% endfor %}
</ul>
可以看到它的使用方式不再和
ejs一样,ejs的模板语法为<%%>,这里要稍加区分。同时在循环结尾处,必须要有
我们创建一个对象数组
var items = [{ name: '张三', age: 20 }, { name: '王五', age: 19 }]
在页面中这样使用
<ul>
{% for item in items%}
<ol>{{item.name}} - {{item['age']}}</ol>
{% endfor%}
</ul>
判断
我们创建一个布尔类型变量
var isDelete = true
app.get("/", (req, res) => {
res.render("index.html",{isDelete})
})
在页面中这样使用
{% if isDelete %}
<h3>欢迎登陆</h3>
{% else %}
<h3>请登陆</h3>
{% endif %}
同样,{%endif%} 也是不可缺少的。
因为isDelete的值是true,那么页面会显示"欢迎登陆"
输出效果

项目目录
使用Express写接口
- 创建基本的服务器
- 创建API路由模块
- 编写GET接口
- 编写POST接口
总结代码
- 服务器代码
// 导入 express
const express = require('express')
// 创建服务器实例
const app = express()
// 配置解析表单数据的中间件
app.use(express.urlencoded({ extended: false }))
// 必须在配置 cors 中间件之前,配置 JSONP 的接口
app.get('/api/jsonp', (req, res) => {
// TODO: 定义 JSONP 接口具体的实现过程
// 1. 得到函数的名称
const funcName = req.query.callback
// 2. 定义要发送到客户端的数据对象
const data = { name: 'zs', age: 22 }
// 3. 拼接出一个函数的调用
const scriptStr = `${funcName}(${JSON.stringify(data)})`
// 4. 把拼接的字符串,响应给客户端
res.send(scriptStr)
})
// 一定要在路由之前,配置 cors 这个中间件,从而解决接口跨域的问题
const cors = require('cors')
app.use(cors())
// 导入路由模块
const router = require('./16.apiRouter')
// 把路由模块,注册到 app 上
app.use('/api', router)
// 启动服务器
app.listen(80, () => {
console.log('express server running at http://127.0.0.1')
})
- API 路由模块
const express = require('express')
const router = express.Router()
// 在这里挂载对应的路由
router.get('/get', (req, res) => {
// 通过 req.query 获取客户端通过查询字符串,发送到服务器的数据
const query = req.query
// 调用 res.send() 方法,向客户端响应处理的结果
res.send({
status: 0, // 0 表示处理成功,1 表示处理失败
msg: 'GET 请求成功!', // 状态的描述
data: query, // 需要响应给客户端的数据
})
})
// 定义 POST 接口
router.post('/post', (req, res) => {
// 通过 req.body 获取请求体中包含的 url-encoded 格式的数据
const body = req.body
// 调用 res.send() 方法,向客户端响应结果
res.send({
status: 0,
msg: 'POST 请求成功!',
data: body,
})
})
// 定义 DELETE 接口
router.delete('/delete', (req, res) => {
res.send({
status: 0,
msg: 'DELETE请求成功',
})
})
module.exports = router
CORS跨域资源共享
接口的跨域问题
刚才编写的 GET 和 POST接口,存在一个很严重的问题:不支持跨域请求。
解决接口跨域问题的方案主要有两种:
- CORS(主流的解决方案,推荐使用)
- JSONP(有缺陷的解决方案:只支持 GET 请求)
使用 cors 中间件解决跨域问题
cors 是 Express 的一个第三方中间件。通过安装和配置 cors 中间件,可以很方便地解决跨域问题。使用步骤分为如下 3 步:
- 运行 npm install cors 安装中间件
- 使用 const cors = require(‘cors’) 导入中间件
- 在路由之前调用 app.use(cors()) 配置中间件
CORS
CORS (Cross-Origin Resource Sharing,跨域资源共享)由一系列 HTTP 响应头组成,这些 HTTP 响应头决定浏览器是否阻止前端 JS 代码跨域获取资源。
浏览器的同源安全策略默认会阻止网页“跨域”获取资源。但如果接口服务器配置了 CORS 相关的 HTTP 响应头,就可以解除浏览器端的跨域访问限制。
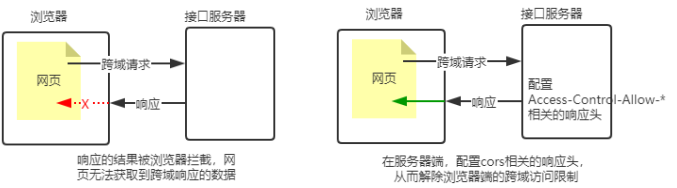
注意:
- CORS 主要在服务器端进行配置。客户端浏览器无须做任何额外的配置,即可请求开启了 CORS 的接口。
- CORS 在浏览器中有兼容性。只有支持 XMLHttpRequest Level2 的浏览器,才能正常访问开启了 CORS 的服务端接口(例如:IE10+、Chrome4+、FireFox3.5+)。
CORS 响应头部 - Access-Control-Allow-Origin
响应头部中可以携带一个 Access-Control-Allow-Origin 字段,其语法如下:
Access-Controlj-Allow-Origin:< origin > | *
其中,origin 参数的值指定了允许访问该资源的外域 URL。
例如,下面的字段值将只允许来自 http://itcast.cn 的请求:
res.setHeader('Access-Control-Allow-Origin','http://itcast.cn')
如果指定了 Access-Control-Allow-Origin 字段的值为通配符 * ,表示允许来自任何域的请求,示例代码如下:
res.setHeader('Access-Control-Allow-Origin','*')
CORS 响应头部 - Access-Control-Allow-Headers
默认情况下,CORS 仅支持客户端向服务器发送如下的 9 个请求头:
Accept、Accept-Language、Content-Language、DPR、Downlink、Save-Data、Viewport-Width、Width 、Content-Type (值仅限于 text/plain、multipart/form-data、application/x-www-form-urlencoded 三者之一)
如果客户端向服务器发送了额外的请求头信息,则需要在服务器端,通过 Access-Control-Allow-Headers 对额外的请求头进行声明,否则这次请求会失败!
//允许客户端额外向服务器发送Content-Type 请求头和X-Custom-Header请求头
//注意:多个请求头之间使用英文的逗号进行分隔
res.setHeader('Access-Control-Allow-Headers','Content-Type,X-Custom-Header')
注意:多个请求头之间使用英文的逗号进行分隔
CORS 响应头部 - Access-Control-Allow-Methods
默认情况下,CORS 仅支持客户端发起 GET、POST、HEAD 请求。
如果客户端希望通过 PUT、DELETE 等方式请求服务器的资源,则需要在服务器端,通过 Access-Control-Alow-Methods来指明实际请求所允许使用的 HTTP 方法。
示例代码如下:
//只允许 POST,GET,DELETE,HEAD请求方法
res.setHeader('Access-Control-Allow-Methods','POST,GET,DELETE,HEAD')
//允许所有的HTTP请求方法
res.setHeader('Access-Control-Allow-Methods','*')
CORS请求的分类
客户端在请求CORS接口时,根据请求方式和请求头的不同,可以将 CORS 的请求分为两大类,分别是:
- 简单请求
- 预检请求
简单请求
同时满足以下两大条件的请求,就属于简单请求:
请求方式:GET、POST、HEAD 三者之一HTTP 头部信息不超过以下几种字段:无自定义头部字段、Accept、Accept-Language、Content-Language、DPR、Downlink、Save-Data、Viewport-Width、Width 、Content-Type(只有三个值application/x-www-form- urlencoded、multipart/form-data、text/plain)
预检请求
只要符合以下任何一个条件的请求,都需要进行预检请求:
- 请求方式为 GET、POST、HEAD 之外的请求 Method 类型
- 请求头中包含自定义头部字段
- 向服务器发送了 application/json 格式的数据
在浏览器与服务器正式通信之前,浏览器会先发送 OPTION 请求进行预检,以获知服务器是否允许该实际请求,所以这一次的 OPTION 请求称为“预检请求”。服务器成功响应预检请求后,才会发送真正的请求,并且携带真实数据。
简单请求和预检请求的区别
简单请求的特点:客户端与服务器之间只会发生一次请求。
预检请求的特点:客户端与服务器之间会发生两次请求,OPTION 预检请求成功之后,才会发起真正的请求。
跨域写JSONP接口
回顾jsonp的概念和特点
概念:浏览器端通过< script >标签的src属性,请求服务器上的数据,同时服务器返回一个函数调用。这种请求方式叫JSONP。
特点:JSONP不属于真正Ajax请求,因为它没有使用XMLttpReuest这个对象。JSONP仅支持GET请求,不支持POST,PUT,DELETE等请求。
创建JSONP接口的注意事项
如果项目中已经配置了 CORS 跨域资源共享,为了防止冲突,必须在配置 CORS 中间件之前声明 JSONP 的接口。否则JSONP 接口会被处理成开启了 CORS 的接口。示例代码如下:
const express = require('express')
// 创建服务器实例
const app = express()
// 配置解析表单数据的中间件
app.use(express.urlencoded({ extended: false }))
// 必须在配置 cors 中间件之前,配置 JSONP 的接口
app.get('/api/jsonp', (req, res) => {
// TODO: 定义 JSONP 接口具体的实现过程
// 1. 得到函数的名称
const funcName = req.query.callback
// 2. 定义要发送到客户端的数据对象
const data = { name: 'zs', age: 22 }
// 3. 拼接出一个函数的调用
const scriptStr = `${funcName}(${JSON.stringify(data)})`
// 4. 把拼接的字符串,响应给客户端
res.send(scriptStr)
})
在网页中使用jQuery发起JSONP请求
调用 $.ajax() 函数,提供 JSONP 的配置选项,从而发起 JSONP 请求,示例代码如下:
<body>
<button id="btnGET">GET</button>
<button id="btnPOST">POST</button>
<button id="btnDelete">DELETE</button>
<button id="btnJSONP">JSONP</button>
<script>
$(function () {
// 1. 测试GET接口
$('#btnGET').on('click', function () {
$.ajax({
type: 'GET',
url: 'http://127.0.0.1/api/get',
data: { name: 'zs', age: 20 },
success: function (res) {
console.log(res)
},
})
})
// 2. 测试POST接口
$('#btnPOST').on('click', function () {
$.ajax({
type: 'POST',
url: 'http://127.0.0.1/api/post',
data: { bookname: '水浒传', author: '施耐庵' },
success: function (res) {
console.log(res)
},
})
})
// 3. 为删除按钮绑定点击事件处理函数
$('#btnDelete').on('click', function () {
$.ajax({
type: 'DELETE',
url: 'http://127.0.0.1/api/delete',
success: function (res) {
console.log(res)
},
})
})
// 4. 为 JSONP 按钮绑定点击事件处理函数
$('#btnJSONP').on('click', function () {
$.ajax({
type: 'GET',
url: 'http://127.0.0.1/api/jsonp',
dataType: 'jsonp',
success: function (res) {
console.log(res)
},
})
})
})
</script>
</body>
MQL数据库
- 常用的数据库代码
-- 通过 * 把 users 表中所有的数据查询出来
-- select * from users
-- 从 users 表中把 username 和 password 对应的数据查询出来
-- select username, password from users
-- 向 users 表中,插入新数据,username 的值为 tony stark password 的值为 098123
-- insert into users (username, password) values ('tony stark', '098123')
-- select * from users
-- 将 id 为 4 的用户密码,更新成 888888
-- update users set password='888888' where id=4
-- select * from users
-- 更新 id 为 2 的用户,把用户密码更新为 admin123 同时,把用户的状态更新为 1
-- update users set password='admin123', status=1 where id=2
-- select * from users
-- 删除 users 表中, id 为 4 的用户
-- delete from users where id=4
-- select * from users
-- 演示 where 子句的使用
-- select * from users where status=1
-- select * from users where id>=2
-- select * from users where username<>'ls'
-- select * from users where username!='ls'
-- 使用 AND 来显示所有状态为0且id小于3的用户
-- select * from users where status=0 and id<3
-- 使用 or 来显示所有状态为1 或 username 为 zs 的用户
-- select * from users where status=1 or username='zs'
-- 对users表中的数据,按照 status 字段进行升序排序
-- select * from users order by status
-- 按照 id 对结果进行降序的排序 desc 表示降序排序 asc 表示升序排序(默认情况下,就是升序排序的)
-- select * from users order by id desc
-- 对 users 表中的数据,先按照 status 进行降序排序,再按照 username 字母的顺序,进行升序的排序
-- select * from users order by status desc, username asc
-- 使用 count(*) 来统计 users 表中,状态为 0 用户的总数量
-- select count(*) from users where status=0
-- 使用 AS 关键字给列起别名
-- select count(*) as total from users where status=0
-- select username as uname, password as upwd from users
实际开发中库、表、行、字段的关系
- 在实际项目开发中,一般情况下,每个项目都对应独立的数据库。
- 不同的数据,要存储到数据库的不同表中,例如:用户数据存储到 users 表中,图书数据存储到 books 表中。
- 每个表中具体存储哪些信息,由字段来决定,例如:我们可以为 users 表设计 id、username、password 这 3 个
字段。 - 表中的行,代表每一条具体的数据。
字段的特殊标识
- PK(Primary Key)主键、唯一标识
- NN(Not Null)值不允许为空
- UQ(Unique)值唯一
- AI(Auto Increment)值自动增长
常用命令
查看版本
mysql --version
启动数据库服务
mysql -uroot -p123456
退出数据库
net stop mysql
关闭数据库服务
net stop mysql
| 命令 | 作用 |
|---|---|
| show databases | 显示所有数据库列表 |
| create database 数据库名 | 创建数据库 |
| create database 数据库名 character set utf8 | 创建数据库并设置编码utf8 |
| alter database 数据库名 character set utf8 | 修改数据库编码 |
| use 数据库名 | 选中指定名称数据库 |
| show tables | 显示数据库中所有表 |
| desc 表名 | 查看表结构 |
| drop database 数据库名 | 删除指定数据库 |
数据库语言
DML:是指对数据库中的表记录的操作,主要包括UPDATE、INSERT、DELETE,这3条命令是用来对数据库里的数据进行增删改操作。
DDL:主要的命令有CREATE、ALTER、DROP等,主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
数据库语句示例
(一)、查询模型
语法:
SELECT
[字段1 [as 别名1],[函数(字段2) ,]…字段n]
FROM 表名
[WHERE where条件]
[GROUP BY 字段]
[HAVING where_contition]
[order 条件]
[limit 条件]
WHERE条件查询
数据库中常用的是where关键字,用于在初始表中筛选查询。它是一个约束声明,用于约束数据,在返回结果集之前起作用。
基本语法: select 字段 from 表 where where条件;
- 主键为32的商品:
select * from goods where goods_id=32;
- 不属于第3个栏目的所有商品
select * from goods where cat_id!=3;
- 本店价格高于3000的商品
select * from goods where shop_price>3000;
- 本店价格低于或等于100的商品
select goods_id,goods_name,shop_price, from goods where shop_price<=100;
- 取出第4个栏目或第11个栏目
select goods_id,goods_name,cat_id from goods where cat_id=3 or cat_id=11;
- 取出100<=价格<=500的商品 shop_price>=100 and shop_price<=500
select goods_name,cat_id,shop_price from goods where shop_price>=100 and shop_price<=500;
between 100 and 500
select goods_name,cat_id,shop_price from goods where shop_price between 100 and 500;
- 取出不属于第3个栏目,且不属于第11个栏目的商品(and 或 not in 分别实现)
select goods_name,cat_id from goods where catid!=3 and cat_id!=11;
select goods_name,cat_id from goods where cat_id not in (3,11);
- 取出第3个栏目下价格<1000或>3000并且点击量>5的商品
select goods_name,cat_id,goods_id,shop_price,click_count from goods where cat_id=3 and (shop_price<1000 or shop_price>3000) and click_count>5;
- 取出价格大于100且小于300,或大于4000且小于5000的商品
select goods_name,cat_id,goods_id,shop_price from goods (shop_price>100 and shop_price<300) or (shop_price>4000 and shop_price<5000);
- 取出名字以‘诺基亚’开头的商品
select goods_id,goods_name from goods where goods_name like "诺基亚%";
- 取出名字为“诺基亚Nxx”的手机
select goods_id,goods_name from goods where goods_name like "诺基亚N__";
- 取出名字不以‘诺基亚’开头的商品
select goods_name from goods where goods_name not like "诺基亚%";
- 取出第3个栏目下面价格在1000到3000之间,并且点击量>5"诺基亚"开头商品
select goods_name,shop_price,click_count from goods where cat_id=3 and click_count>5 and goods_name like "诺基亚%";
GROUPBY分组查询与统计函数
统计函数
如果我们想知道总用户数怎么办?
查询谁是数据表里的首富怎么办?
如果我们想知道用户的平均金额怎么办?
如果我们想知道所有用户的总金额怎么办?
函数名 作用
count() 计算行数
avg() 求平均值
sum() 求和
min() 求最小值
max() 求最大值
基本语法:select 函数(字段) from 表
- 查询所有商品的平均价格
select avg(shop_price) from goods;
- 查询最贵的商品
select max(shop_price) from goods;
- 查询最便宜的商品
select min(shop_price) from goods;
- 查询一共有多少种商品
select count(*) from goods;
- 查询商品的总价格
select sum(shop_price) as allsum from goods;
- 查询本店积压的商品总货款
select sum(shop_price*goods_number) as all from goods;
GROUPBY分组查询
GROUP BY 语句根据一个或多个列对SELECT结果集进行分组。
基本语法:select * from 表 group by 字段
案例:
- 统计每个栏目下商品的平均价格
select avg(shop_price) as avg,cat_id from goods group by cat_id;
- 查询每个栏目下有多少种商品
select count(*),cat_id from goods groupby cat_id;
- 查询每个栏目下最贵的商品
select max(shop_price),cat_id from goods group by cat_id;
HAVAING 筛选
用于对where和group by查询出来的结果集进行过滤,查出满足条件的结果集。它是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作。
基本语法:select * from 表 group by 字段 having 条件
示例:
- 查询每个商品所积压的货款(库存* 单价)
select goods_id,goods_name,goods_number*shop_price from goods;
- 查询该店每个栏目下积压的货款
select sum(goods_number*shop_price),cat_id from goods group by cat_id;
- 查询比市场价格省钱200以上的商品及该商品所省的钱(where having)
select goods_id,goods_name,market_price-shop_price from goods whre market_price-shop_price>200;
select goods_id,goods_name,market_price-shop_price as sheng from goods having sheng>200;
如果我们把where中的market_price-shop_price赋值给sheng where sheng> 200这样会报错 unknown column 'sheng'select goods_id,goods_name,market_price-shop_price as sheng from goods where sheng>200; //报错sheng列找不到
where条件筛选的是磁盘上的表的字段,而sheng是结果集上的字段,结果集查出来的是临时放在内存里的,我们需要筛选结果集上的字段,我们可以将结果集当成表,进一步筛选,只不过不能用where需要用having,where 发挥的比较早,是针对磁盘上的表发挥作用,筛选出结果集。从结果集中进一步筛选需要用having,where与having同时存在,where要放到having前面。
orderby排序
排序是按照某个属性来排的,在数据库中是按照某个列来排的,那有正序也有倒序。
基本语法:select 字段 from 表 order by 字段1 desc/asc,字段n desc/asc
asc 升序排列,从小到大(默认)
desc 降序排列,从大到小
示例:
- 按照价格进行排序
select * from goods order by shop_price asc;
select * from goods order by shop_price desc;
- 按照栏目进行排序
select * from goods order by cat_id asc;
select * from goods order by cat_id desc;
- 按照栏目升序排列后,在每个栏目中按照价格降序排列
select goods_name,cat_id,shop_price from goods order by cat_id,shop_price desc;
limit 限制取出条数
order by一般和limit配合使用功能才会更强大
基本语法:
语法1 select 字段 from 表 order by 字段 关键词 limit 数量
语法2 select 字段 from 表 order by 字段 关键词 limit offset,n
limit n //限制取出条目
limit offset,n //跳过offset条取出n条
示例:
limit 3 //取出0~ 3 取出前3
limit 2,3;//取出前3到前5
- 取出价格最高的前三名商品
select goods_name,shop_price from goods order by shop_price desc limit 0,3;
- 取出点击量前3到前5名的商品
select goods_name,goods_id,click_count from goods order by click_count desc limit 2,3;
多表联合查询
| 类型 | 子类型 | 描述 |
|---|---|---|
| 内连接 | 取得两个表中存在连接匹配关系的记录。内连接使用比较运算符根据每个表共有的列的值匹配两个表中的行。例如,检索 students 和 courses 表中学生学号相同的所有行。 | |
| 隐式的内连接 | 没有INNER JOIN,形成的中间表为两个表的笛卡尔积。 | |
| 显示的内连接 | 有INNER JOIN,形成的中间表为两个表经过ON条件过滤后的笛卡尔积。 | |
| 外连接 | 外连接可以是左向外连接、右向外连接 | |
| 左外连接 | 左表中的所有数据全部取出,然后到对应的右表去找数据,如果找不到数据补null | |
| 右外连接 | 右外连接是左外联接的反向联接,将返回右表的所有行,如果右表的某行在左表中没有匹配行,则将为左表返回空值。 |
内连接
隐式语法1 select 表1.字段 [as 别名],表n.字段 from 表1 [别名],表n where 条件;
显式语法2 select 表1.字段 [as 别名],表n.字段 from 表1 INNER JOIN 表n on 条件;
案例:
取出boy和girl表数据,id相同者为一对
//隐式内连接
select boy.hid,boy.bname,girl.hid,girl.gname from boy,girl where boy.hid=girl.hid
//显式内连接
select boy.hid,boy.bname,girl.hid,girl.gname from boy inner join girl on boy.hid=girl.hid
外联接
左向外联接
语法:select 表1.字段 [as 别名],表n.字段 from 表1 LEFT JOIN 表n on 条件;
案例:
所有男士站出来,找到自己的另一半,没有的以Null补齐
select boy.hid,boy.bname,girl.hid,girl.gname from boy left join girl on boy.hid=girl.hid。
右向外联接
语法 select 表1.字段 [as 别名],表n.字段 from 表1 right JOIN 表n on 条件;
select boy.hid,boy.bname,girl.hid,girl.gname from boy right join girl on boy.hid=girl.hid
在项目中使用Mysql数据库
在项目中操作数据库的步骤
- 安装操作 MySQL 数据库的第三方模块(mysql)
- 通过 mysql 模块连接到 MySQL 数据库
- 通过 mysql 模块执行 SQL 语句

安装mysql模块
mysql 模块是托管于 npm 上的第三方模块。它提供了在 Node.js 项目中连接和操作 MySQL 数据库的能力。想要在项目中使用它,需要先运行如下命令,将 mysql 安装为项目的依赖包:
npm install mysql
配置mysql模块
在使用 mysql 模块操作 MySQL 数据库之前,必须先对 mysql 模块进行必要的配置,主要的配置步骤如下:
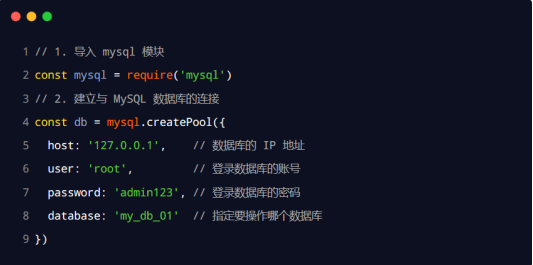
测试mysql模块是否可以正常工作
调用 db.query() 函数,指定要执行的 SQL 语句,通过回调函数拿到执行的结果:
const mysql = require('mysql')
const db = mysql.createPool({
host: '127.0.0.1',
user: 'root',
password: 'root',
database: 'bookman',
})
//检查mysql模块是否正常使用
db.query('SELECT 1', (err, results) => {
if (err) return console.log(err.message);
//只要可以输出[ RowDataPacket { '1': 1 } ]的结果,就证明数据库链接没问题。
console.log(results);
})
查询语句
查询表中数据示例:
const mysql = require('mysql')
const db = mysql.createPool({
host: '127.0.0.1',
user: 'root',
password: 'root',
database: 'bookman',
})
db.query('SELECT * FROM tb_book', (err, results) => {
//查询失败
if (err) return console.log(err.message);
//查询成功
//如果执行的是select查询语句,则返回的是数组
console.log(results);
})
插入数据
向表中插入数据,示例代码如下。
- 便捷方式
//插入数据 简化形式
const user = { username: 'liyu2', password: '49023dfs!2' }
//待执行的sql语句
const sqlStr = 'INSERT INTO tb_user SET ?'
//使用数组的形式,依次为?占位符指定具体的值。
db.query(sqlStr, user, (err, results) => {
//失败了
if (err) return console.log(err.message);
//成功了
if (results.affectedRows) {
console.log('插入数据成功');
}
})
注意:
这种方法适合插入多项属性时使用
db.query里的第二个值一定是对象,如果是多个值,就用中括号包含
如果执行的是insert into语句,则result是一个对象
可以通过affectedRows属性,来判断是否插入成功
- 初始形式
//插入数据
const list = { username: 'liyu3', password: '23123' }
//待执行的sql语句
const sqlstr = 'INSERT INTO tb_user SET ?'
//使用数组的形式,依次为?占位符指定具体的值。
db.query(sqlstr, [list.username, list.password], (err, results) => {
//失败了
if (err) return console.log(err.message);
//成功了
//注意:如果执行的是insert into语句,则result是一个对象
//可以通过affectedRows属性,来判断是否插入成功
if (results.affectedRows) {
console.log('插入数据成功');
}
})
更新数据
可以通过如下方式,更新表中的数据:
//需要更新的数据
const update = { username: 'liyu', password: '3343' }
//要执行的SQL语句
const updateSql = 'UPDATE tb_user SET password=? WHERE username = ?'
//3.调用db.query()执行 SQL 语句的同时,依次为占位符指定具体的值
db.query(updateSql, [update.password, update.username], (err, results) => {
if (err) return console.log(err.message);
if (results.affectedRows) { console.log('更新状态成功'); }
})
注意:
执行了update后,返回的也是一个对象,可以通过.affectedRows来判断是否成功
- 便捷方式
const update2 = { username: 'liyu2', password: '111' }
const updateSql1 = 'UPDATE tb_user SET ? WHERE username=?'
db.query(updateSql1, [update2, update2.username], (err, results) => {
if (err) return console.log(err.message);
if (results.affectedRows) { console.log('更新成功'); }
})
注意:
在是使用便捷方式开发代码时需要注意,db.query里的第二参数里,第一个值一定是对象。
删除数据
在删除数据时,推荐根据 id 这样的唯一标识,来删除对应的数据。示例如下:
const sqlStr = 'delete from tb_user where username = ?'
db.query(sqlStr, 'liyu2', (err, results) => {
if (err) return console.log(err.message);
if (results.affectedRows) {
console.log('删除成功');
}
})
注意:
调用db.query()执行SQL语句时,为占位符指定具体的值
如果SQL里有多个占位符,则必须使用数组为每个占位符指定具体的值
如果SQL里只有一个占位符,则可以省略数组
标记删除
使用 DELETE 语句,会把真正的把数据从表中删除掉。为了保险起见,推荐使用标记删除的形式,来模拟删除的动作。
所谓的标记删除,就是在表中设置类似于 status 这样的状态字段,来标记当前这条数据是否被删除。
当用户执行了删除的动作时,我们并没有执行 DELETE 语句把数据删除掉,而是执行了 UPDATE 语句,将这条数据对应
的 status 字段标记为删除即可。
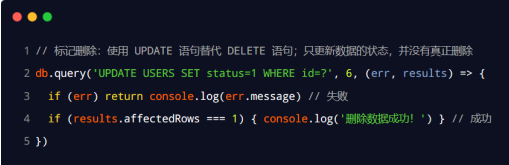
前后端的身份认证
Web开发模式
目前主流的 Web 开发模式有两种,分别是:
- 基于服务端渲染的传统 Web 开发模式
- 基于前后端分离的新型 Web 开发模式
服务端渲染的 Web 开发模式
服务端渲染的概念:服务器发送给客户端的 HTML 页面,是在服务器通过字符串的拼接,动态生成的。因此,客户端不需要使用 Ajax 这样的技术额外请求页面的数据。代码示例如下:
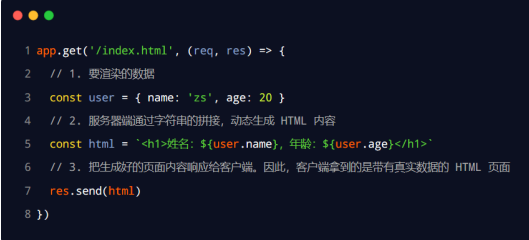
- 服务端渲染的优缺点
优点:
- 前端耗时少。因为服务器端负责动态生成 HTML 内容,浏览器只需要直接渲染页面即可。尤其是移动端,更省电。
- 有利于SEO。因为服务器端响应的是完整的 HTML 页面内容,所以爬虫更容易爬取获得信息,更有利于 SEO。
缺点:
- 占用服务器端资源。即服务器端完成 HTML 页面内容的拼接,如果请求较多,会对服务器造成一定的访问压力。
- 不利于前后端分离,开发效率低。使用服务器端渲染,则无法进行分工合作,尤其对于前端复杂度高的项目,不利于项目高效开发。
前后端分离的 Web 开发模式
前后端分离的概念:前后端分离的开发模式,依赖于 Ajax 技术的广泛应用。简而言之,前后端分离的 Web 开发模式,就是后端只负责提供 API 接口,前端使用 Ajax 调用接口的开发模式。
- 前后端分离的优缺点
优点:
- 开发体验好。前端专注于 UI 页面的开发,后端专注于api 的开发,且前端有更多的选择性。
- 用户体验好。Ajax 技术的广泛应用,极大的提高了用户的体验,可以轻松实现页面的局部刷新。
- 减轻了服务器端的渲染压力。因为页面最终是在每个用户的浏览器中生成的。
缺点:
- 不利于 SEO。因为完整的 HTML 页面需要在客户端动态拼接完成,所以爬虫对无法爬取页面的有效信息。(解决方案:利用 Vue、React 等前端框架的 SSR (server side render)技术能够很好的解决 SEO 问题!)
如何选择前后端的身份认证
不谈业务场景而盲目选择使用何种开发模式都是耍流氓。
- 比如企业级网站,主要功能是展示而没有复杂的交互,并且需要良好的 SEO,则这时我们就需要使用服务器端渲染;
- 而类似后台管理项目,交互性比较强,不需要考虑 SEO,那么就可以使用前后端分离的开发模式。
另外,具体使用何种开发模式并不是绝对的,为了同时兼顾了首页的渲染速度和前后端分离的开发效率,一些网站采用了首屏服务器端渲染 + 其他页面前后端分离的开发模式。
身份认证
身份认证(Authentication)又称“身份验证”、“鉴权”,是指通过一定的手段,完成对用户身份的确认。
- 日常生活中的身份认证随处可见,例如:高铁的验票乘车,手机的密码或指纹解锁,支付宝或微信的支付密码等。
- 在 Web 开发中,也涉及到用户身份的认证,例如:各大网站的手机验证码登录、邮箱密码登录、二维码登录等。
不同开发模式下的身份认证
对于服务端渲染和前后端分离这两种开发模式来说,分别有着不同的身份认证方案:
- 服务端渲染推荐使用
Session 认证机制 - 前后端分离推荐使用
JWT 认证机制
Session认证机制
HTTP 协议的无状态性
HTTP 协议的无状态性,指的是客户端的每次 HTTP 请求都是独立的,连续多个请求之间没有直接的关系,服务器不会主动保留每次 HTTP 请求的状态。

如何突破 HTTP 无状态的限制
对于超市来说,为了方便收银员在进行结算时给 VIP 用户打折,超市可以为每个 VIP 用户发放会员卡。
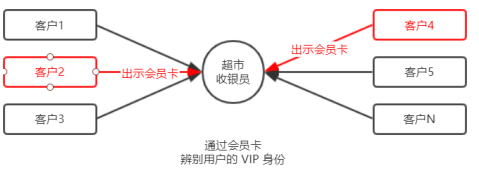
注意:
现实生活中的会员卡身份认证方式,在 Web 开发中的专业术语叫做 Cookie。
什么是cookie
Cookie 是存储在用户浏览器中的一段不超过 4 KB 的字符串。它由一个名称(Name)、一个值(Value)和其它几个用于控制 Cookie 有效期、安全性、使用范围的可选属性组成。
不同域名下的 Cookie 各自独立,每当客户端发起请求时,会自动把当前域名下所有未过期的 Cookie 一同发送到服务器。
cookie的几大特性:
- 自动发送
- 域名独立
- 过期时限
4kb限制
Cookie 在身份认证中的作用
客户端第一次请求服务器的时候,服务器通过响应头的形式,向客户端发送一个身份认证的 Cookie,客户端会自动将 Cookie 保存在浏览器中。
随后,当客户端浏览器每次请求服务器的时候,浏览器会自动将身份认证相关的 Cookie,通过请求头的形式发送给服务器,服务器即可验明客户端的身份。

Cookie 不具有安全性
由于 Cookie 是存储在浏览器中的,而且浏览器也提供了读写 Cookie 的 API,因此 Cookie 很容易被伪造,不具有安全性。因此不建议服务器将重要的隐私数据,通过 Cookie 的形式发送给浏览器。
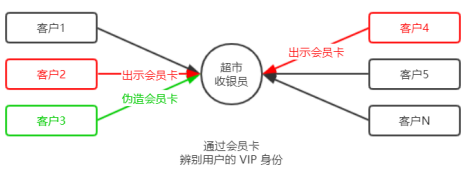
注意:
千万不要使用 Cookie 存储重要且隐私的数据!比如用户的身份信息、密码等。
提高身份认证的安全性
为了防止客户伪造会员卡,收银员在拿到客户出示的会员卡之后,可以在收银机上进行刷卡认证。只有收银机确认存在的会员卡,才能被正常使用。

这种“会员卡 + 刷卡认证”的设计理念,就是 Session 认证机制的精髓。
Session简单介绍
session 是另一种记录客户状态的机制,不同的是 Cookie 保存在客户端浏览器中,而 session 保存在服务器上。
-
Session的用途:
session运行在服务器端,当客户端第一次访问服务器时,可以将客户的登录信息保存。
当客户访问其他页面时,可以判断客户的登录状态,做出提示,相当于登录拦截。
session可以和Redis或者数据库等结合做持久化操作,当服务器挂掉时也不会导致某些客户信息(购物车)
丢失。
Session的工作原理
当浏览器访问服务器并发送第一次请求时,服务器端会创建一个session对象,生成一个类似于
key,value的键值对,然后将key(cookie)返回到浏览器(客户)端,浏览器下次再访问时,携带key(cookie),找到对应的session(value)。
客户的信息都保存在session中。
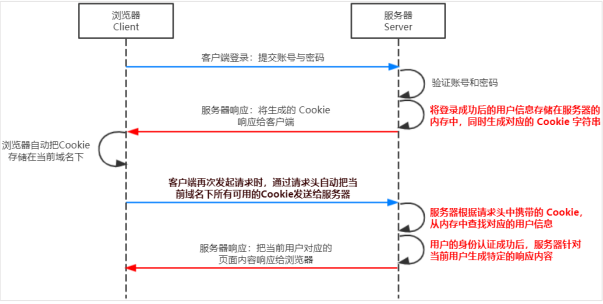
Session与Cookie的区别
- session与cookie都是由服务器生产的
- session存储在服务器端,而cookie存储在客户端或者浏览器端
- 客户端发送请求时会自动携带,本域名下,未过期的cookie
- 都具有生命周期
- 单个cookie不超过4kb,有的浏览器限制保存20个cookie
注意:
服务器一重启,内存就清空,session(保存到内存中)就没了。
在Express中使用Session认证
在 Express 项目中,只需要安装 express-session 中间件,即可在项目中使用 Session 认证:
npm install express-session
配置express-session中间件
express-session 中间件安装成功后,需要通过 app.use() 来注册 session 中间件,示例代码如下:
// TODO_01:请配置 Session 中间件
const session = require('express-session')
app.use(session({
secret: 'CMS',
resave: false,
saveUninitialized: true,
}))
向 session 中存数据
当 express-session 中间件配置成功后,即可通过 req.session 来访问和使用 session 对象,从而存储用户的关键信息:
// 登录的 API 接口
app.post('/api/login', (req, res) => {
// 判断用户提交的登录信息是否正确
if (req.body.username !== 'admin' || req.body.password !== '000000') {
return res.send({ status: 1, msg: '登录失败' })
}
// TODO_02:请将登录成功后的用户信息,保存到 Session 中
//注意:只有成功配置了express-session中间件后,才可以使用req.session这个中间件
req.session.user = req.body //将用户信息保存到session中
req.session.islogin = true //用户的登陆状态
res.send({ status: 0, msg: '登录成功' })
})
从 session 中取数据
可以直接从req.session对象上获取之间存储的数据。
// 获取用户姓名的接口
app.get('/api/username', (req, res) => {
// TODO_03:请从 Session 中获取用户的名称,响应给客户端
//判断用户登陆
if (!req.session.islogin) {
return res.send({ status: 1, msg: 'fail' })
}
res.send({ status: 0, msg: 'success', username: req.session.user.username })
})
清空session
调用 req.session.destroy() 函数,即可清空服务器保存的 session 信息。
// 退出登录的接口
app.post('/api/logout', (req, res) => {
// TODO_04:清空 Session 信息
req.session.destroy()
req.send({
status: '0',
mag: '退出登陆成功'
})
})
express-session的常用参数:
1. name - cookie的名字(原属性名为 key)。(默认:’connect.sid’)
2. store - session存储实例
3. secret - 用它来对session cookie签名,防止篡改
4. cookie - session cookie设置 (默认:{ path: ‘/‘, httpOnly: true,secure: false, maxAge: null })
5. genid - 生成新session ID的函数 (默认使用uid2库)
6. rolling - 在每次请求时强行设置cookie,这将重置cookie过期时间(默认:false)
7. resave - 强制保存session即使它并没有变化 (默认: true)
8. proxy - 当设置了secure cookies(通过”x-forwarded-proto” header )时信任反向代理。当设定为true时,
”x-forwarded-proto” header 将被使用。当设定为false时,所有headers将被忽略。当该属性没有被设定时,将使用Express的trust proxy。
9. saveUninitialized - 强制将未初始化的session存储。当新建了一个session且未设定属性或值时,它就处于
未初始化状态。在设定一个cookie前,这对于登陆验证,减轻服务端存储压力,权限控制是有帮助的。(默认:true)
10. unset - 控制req.session是否取消(例如通过 delete,或者将它的值设置为null)。这可以使session保持
express-session的常用方法:
1. Session.destroy():删除session,当检测到客户端关闭时调用。
2. Session.reload():当session有修改时,刷新session。
3. Session.regenerate():将已有session初始化。
4. Session.save():保存session。
使用时的基本思想
sessio 与 cookie:
基于HTTP协议,HTTP是一种无状态的协议
-
为什么有session与cookie
web 1.0:资源共享,
web 2.0: 交互,多部操作,依赖数据
session与cookie:来实现状态的记录,解决Http无状态的缺陷。 -
session和cookie的区别和特点:
- session与cookie都是由服务器生产的
- session存储在服务器端,而cookie存储在客户端或者浏览器端
- 客户端发送请求时会自动携带,本域名下,未过期的cookie
- 都具有生命周期
-
如何配置
和multer类似,配置好multer,才能在req,file,同样,配置好express-session,才能req.session -
使用express-session进行开发
登陆页
/login 渲染登陆页面
/api/login 以post方式去访问,提交数据(用户名和密码)
通过验证,返回登陆成功,存储session(用户名和密码)
前台:失败:返回登陆页
成功:跳转到首页
首页:渲染首页(验证是否登陆成功)
/api/username get 返回当前是否登陆成功 (session取数据)
失败:提示信息
成功:提示信息,返回用户名
前台:失败:跳转到登陆页面
成功:提示用户信息,展示用户名
/api/logout 退出登录:摧毁session,返回信息。
前台:退出成功:跳转到登陆页面
使用案例:
//配置中间件
app.use(session({
secret: 'this is string key', // 可以随便写。一个 String 类型的字符串,作为服务器端生成 session 的签名
name:'session_id',/*保存在本地cookie的一个名字 默认connect.sid 可以不设置*/
resave: false, /*强制保存 session 即使它并没有变化,。默认为 true。建议设置成 false。*/
saveUninitialized: true, //强制将未初始化的 session 存储。 默认值是true 建议设置成true
cookie: {
maxAge:5000 /*过期时间*/
}, /*secure https这样的情况才可以访问cookie*/
//设置过期时间比如是30分钟,只要游览页面,30分钟没有操作的话在过期
rolling:true //在每次请求时强行设置 cookie,这将重置 cookie 过期时间(默认:false)
}))
JWT 认证机制
了解 Session 认证的局限性
Session 认证机制需要配合 Cookie 才能实现。由于 Cookie 默认不支持跨域访问,所以,当涉及到前端跨域请求后端接口的时候,需要做很多额外的配置,才能实现跨域 Session 认证。
注意:
- 当前端请求后端接口不存在跨域问题的时候,推荐使用 Session 身份认证机制。
- 当前端需要跨域请求后端接口的时候,不推荐使用 Session 身份认证机制,推荐使用 JWT 认证机制。
JWT
JWT(英文全称:JSON Web Token)是目前最流行的跨域认证解决方案。
JWT的工作原理

总结:用户的信息通过Tocken字符串的形式,保存在客户端浏览器中,服务器通过还原Tocken字符串的形式来验证用户的身份。
session认证和JWT认证的区别:
session认证存放在服务器中,JWT认证存放在浏览器中
JWT的组成
Header(头部),Payload(有效荷载),Signature(签名)
三者之间用英文的“.”分隔,格式如下:
Header.Payload,Signature
JWT 的三个部分各自代表的含义
JWT 的三个组成部分,从前到后分别是 Header、Payload、Signature。
其中:
- Payload 部分才是真正的用户信息,它是用户信息经过加密之后生成的字符串。
- Header 和 Signature 是安全性相关的部分,只是为了保证 Token 的安全性。
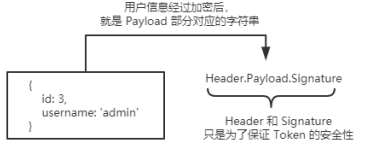
JWT 的使用方式
客户端收到服务器返回的 JWT 之后,通常会将它储存在 localStorage 或 sessionStorage 中。
此后,客户端每次与服务器通信,都要带上这个 JWT 的字符串,从而进行身份认证。推荐的做法是把 JWT 放在 HTTP 请求头的 Authorization 字段中,格式如下:
Authorization:Bearer < token >
在 Express 中使用 JWT
安装 JWT 相关的包
运行如下命令,安装两个JWT相关的包:
npm install jsonwebtoken express-jwt
其中:
jsonwebtoken 用于生成 JWT 字符串
express-jwt 用于将 JWT 字符串解析还原成 JSON 对象
导入JWT相关的包
使用require() 函数,分别导入JWT相关的两个包:
// TODO_01:安装并导入 JWT 相关的两个包,分别是 jsonwebtoken 和 express-jwt
const jwt = require('jsonwebtoken')
const expressJwt = require('express-jwt')
定义 secret 密钥
为了保证 JWT 字符串的安全性,防止 JWT 字符串在网络传输过程中被别人破解,我们需要专门定义一个用于加密和解密的 secret 密钥:
- 当生成 JWT 字符串的时候,需要使用 secret 密钥对用户的信息进行加密,最终得到加密好的 JWT 字符串
- 当把 JWT 字符串解析还原成 JSON 对象的时候,需要使用 secret 密钥进行解密
// TODO_02:定义 secret 密钥,建议将密钥命名为 secretKey
const secretKey = 'liyu No1'
在登录成功后生成 JWT 字符串
调用 jsonwebtoken 包提供的 sign() 方法,将用户的信息加密成 JWT 字符串,响应给客户端:
// 登录成功
// TODO_03:在登录成功之后,调用 jwt.sign() 方法生成 JWT 字符串。并通过 token 属性发送给客户端
const tokenStr = jwt.sign({ username: userinfo.username }, secretKey, { expiresIn: '30s' })
res.send({
status: 200,
message: '登录成功!',
token: 'tokenStr' // 要发送给客户端的 token 字符串
})
将JWT字符串还原为JSON对象
客户端每次在访问那些有权限接口的时候,都需要主动通过请求头中的 Authorization 字段,将 Token 字符串发送到服务器进行身份认证。
此时,服务器可以通过 express-jwt 这个中间件,自动将客户端发送过来的 Token 解析还原成 JSON 对象:
app.use(expressJwt({ secret: 'secretKey' }.unless({ path: [/^\/api\//] })))
使用 req.user 获取用户信息
当 express-jwt 这个中间件配置成功之后,即可在那些有权限的接口中,使用 req.user 对象,来访问从 JWT 字符串中解析出来的用户信息了,示例代码如下:
// 这是一个有权限的 API 接口
app.get('/admin/getinfo', function (req, res) {
// TODO_05:使用 req.user 获取用户信息,并使用 data 属性将用户信息发送给客户端
console.log(req.user);
res.send({
status: 200,
message: '获取用户信息成功!',
data: req.user, // 要发送给客户端的用户信息
})
})
捕获解析JWT失败后产生的错误
当使用express-jwt解析Token字符串时,如果客户端发送过来的Tocken字符串过期,或者不合法,就会产生一个解析失败的错误,我们可以使用Express的错误中间件,捕获这个错误并进行相关的处理,示例代码如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0cggYkzU-1657621329103)(./图片/Snipaste_2022-05-04_08-47-49.png)]
node.js中的流
项目中数据加密和后台验证
一、对密码进行加密处理
JavaScript使用
CryptoJS加解密。CryptoJS时一个JavaScript的加解密的工具包。它支持多种的算法:MD5、SHA1、SHA2、SHA3、RIPEMD-160 哈希散列,进行 AES、DES、Rabbit、RC4、Triple DES 加解密。在项目中如果要对前后端传输的数据双向加密, 比如避免使用明文传输用户名,密码等数据。 就需要对前后端数据用同种方法进行加密,方便解密。
使用步骤:
- 运行如下命令,安装
CryptoJS:
npm i crypto-js
- 在
/login.js中,导入crypto-js:
const crypto = require('crypto-js')
- 以
ASE进行纯文本加密:
//加密
var a=crypto.AES.encrypt("abc","key").toString(); //SecrectKey 秘钥
//解密
var b=crypto.AES.decrypt(a,"key").toString(crypto.enc.Utf8); //按照UTF8编码解析出原始字符串
二、表单校验规则
在实际开发中,前后端都需要对表单的数据进行合法性的验证,而且,后端做为数据合法性验证的最后一个关口,在拦截非法数据方面,起到了至关重要的作用。使用第三方数据验证模块,来降低出错率、提高验证的效率与可维护性。
步骤:
- 安装
joi包,为表单中携带的每个数据项,定义验证规则:
npm install joi
- 安装
@escook/express-joi中间件,来实现自动对表单数据进行验证的功能:
npm i @escook/express-joi
- 新建
/schema/login.js用户信息验证规则模块:
const joi = require('joi')
/**
* string() 值必须是字符串
* alphanum() 值只能是包含 a-zA-Z0-9 的字符串
* min(length) 最小长度
* max(length) 最大长度
* required() 值是必填项,不能为 undefined
* pattern(正则表达式) 值必须符合正则表达式的规则
*/
// 用户名的验证规则
const username = joi.string().required();
// 密码的验证规则
const password = joi.string().pattern(/^[\S]{6,12}$/).required();
// 登录表单的验证规则对象
exports.login_schema = {
// 表示需要对 req.body 中的数据进行验证
body: {
username,
password,
},
}
- 修改
/router/admin/login.js中的代码:
// 1. 导入验证表单数据的中间件
const expressJoi = require('@escook/express-joi')
// 2. 导入需要的验证规则对象
const { login_schema } = require('../../schema/login');
// 3登录功能
router.post("/",expressJoi(login_schema),(req,res)=>{});
- 在
index.js的全局错误级别中间件中,捕获验证失败的错误,并把验证失败的结果响应给客户端:
const joi = require('joi')
// 错误中间件
app.use(function (err, req, res, next) {
// 数据验证失败
if (err instanceof joi.ValidationError) return res.send(err);
// 未知错误
res.send(err)
})
四种常见的POST提交数据方法
HTTP协议是以ASCII码进行传输,建立在TCP/IP协议之上的应用层规范。规划把HTTP请求分成三个部分:转态行,请求头,消息主体。协议规定POST请求提交的数据必须放到消息主题(entity-body)中,但协议并没有规定必须使用什么编码方式Content-Type。
服务端根据请求头(headers)中的Content-Type字段来获知请求中的消息主体是用何种方式编码,再对主体进行解析。所以说到POST提交数据方案,包含了Content-Type和消息主体编码方式两部分。Content-Type的四种值分别代表四种方式,具体如下:
- 方式一:application/x-www-form-urlencoded
浏览器的原生form表单,如果不设置enctype属性,那么最终就会以 application/x-www-form-urlencoded方式提交数据。Content-Type被指定为application/x-www-form-urlencoded提交的数据按照key=val&key=val的方式进行编码,并且key和val都进行了URL转码。服务端例如 PHP 中,使用$_POST[′key′]可以获取到值。
-
方式二:multipart/form-data
常见的POST数据提交的方式。这种方式支持文件上传,不过必须要设置form的enctyped等于这个值。使用multipart/form-data方式会生成了一个boundary 来分割不同的字段,为了避免与正文重复,boundary是一段很长的随机拼接的字符串。然后Content-Type指明数据是以mutipart/form-data来编码并包括进本次请求的boundary 值。消息主体最后以 --boundary–标示结束。 -
方式三:application/json
由于JSON规范的流行,现在越来越多的开发者将application/json这个Content-Type作为响应头。用来告诉服务端消息主体是序列化后的JSON字符串。除了低版本IE之外各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理JSON的函数,JSON能格式支持比键值对复杂得多的结构化数据,普通键值对中的值只能是字符串,而使用json,键值对可以重复嵌套。 -
方式四:text/xml
它是一种使用HTTP作为传输协议,XML作为编码方式的远程调用规范。不过后来使用很少。也许在十多年前,在json还未出来之前数据交互对接。
总之application/x-www-form-urlencoded和multipart/form-data两种POST方式都是浏览器原生支持的,是普遍使用的两种方式,application/json是现在比较流行的新趋势。
文件上传
multer
- 安装multer
npm i multer
- 导入multer
const multer = require('multer')
- 配置multer接收到的文件存储的文件夹和,存放的图片的名字
//上传文件存放路径、及文件命名
const storage = multer.diskStorage({
destination: path.join(__dirname ,'../static/uploads'), //确定上传文件的物理位置
filename: function (req, file, cb) { //自定义设置文件的名字,根据上传时间的时间戳来命名
let type = file.originalname.split('.')[1]
cb(null, `${file.fieldname}-${Date.now().toString(16)}.${type}`)
}
})
1.sotrage是一个配置对象。他是通过multer.diskstorage存储引擎生成的。multer.diskstorage需要传递一个配置对象,这里的配置对象里面接收两个参数。第一个参数为destination,它的值为一个路径字符串,代表的含义是当multer处理完成前端传递过来的文件之后要把这个文件存储在哪里。这个文件夹无需手动创建,在接受文件的时候会自动创建。这里建议使用path模块进行拼接,不容易出错。第二个参数为一个回调函数,这里形参要用三个进行占位。multer中间件在解析前端提交的文件的时候会调用这个方法,调用的时候会给这个filename指向的函数传递三个参数,第二个值为前端传递过来文件信息,第三个参数cb为一个函数,cb函数调用的第二个参数指定的就是当前解析完成后的保存到destination指向的目录的文件名。
- 应用这个配置到multer实例里面
const upload = multer({storage});
- 在需要接收文件的路由里面应用upload.single(‘file’)中间件
(1).这个file是前端提交表单过来的时候表单的字段名称。
(2).upload是用multer这个库里的顶级构造函数生成的实例。
- 总体思路梳理:
实际网页开发当中,我们前端需要向后端提交一些像mp4,mp3,图片系列的东西,需要在后端进行接收。那么这里就可以使用Multer中间件来接收文件,对前端传递过来的文件做一些处理。
-
multer是啥? Multer是Express官方推出的,用于node.js 处理前端以multipart/form-data请求数据处理的一个中间件。注意: Multer 不会处理任何非 multipart/form-data 类型的表单数据
-
原理: Multer实例的single(‘###’) 是一个方法,这个方法被当作中间件放在某一个路由上时。就会给express 的 request 对象中添加一个 body 对象 以及 file 或 files 对象 。 body 对象包含表单的文本域信息,file 或 files 对象包含对象表单上传的文件信息。下图就是req.file的模样。当前端请求后台接口。匹配当前路由的时候,先经过这个multer中间件,这个中间件就会解析前端传过来的文件,会把文件保存在上面第三步配置文件解析完成后的文件夹内,名字也会重命名成上面第三步配置文件解析完成的文件名。同时,会在req的身上挂载一个file对象。这个file对象就是当前上传文件的信息。我们可以通过req.file.filename拿到这个重命名后的文件名,然后把这个文件名保存到数据库里面。前端如果想访问之前上传的图片,后台只需要把数据库里的文件名取到,随后映射成我们请求的路径,去请求public静态资源下的存放这些文件的文件夹就可以了。
-
multer是一个中间件,我建议把这个中间件写成一个单独的文件,最后把配置好的multer实例暴露出去,在需要他的路由里面当作中间件去应用它。就可以很快捷的处理前端发送过来的文件。而无需每个文件都写一遍。也更加符合我们模块化编程的思想。下图是我multer文件的配置。
layui富文本编辑器的使用
富文本编辑器,Multi-function Text Editor, 简称 MTE, 是一种可内嵌于浏览器,所见即所得的文本编辑器。它提供类似于 Microsoft Word 的编辑功能,容易被不会编写 HTML 的用户并需要设置各种文本格式的用户所喜爱。
富文本编辑器不同于文本编辑器,程序员可到网上下载免费的富文本编辑器内嵌于自己的网站或程序里(当然付费的功能会更强大些),方便用户编辑文章或信息。
layui 富文本编辑器(layedit):
-
使用:
<textarea id="demo" style="display: none;"></textarea> layui.use(['layedit'],function(){ layedit.build("demo") }) -
layedit基础的方法:
方法名 描述 var index = layedit.build(id, options) 用于建立编辑器的核心方法index:即该方法返回的索引参数 id: 实例元素(一般为textarea)的id值参数 options:编辑器的可配置项,下文会做进一步介绍 layedit.set(options) 设置编辑器的全局属性即上述build方法的options layedit.getContent(index) 获得编辑器的内容参数 index: 即执行layedit.build返回的值 layedit.getText(index) 获得编辑器的纯文本内容参数 index: 同上 layedit.sync(index) 用于同步编辑器内容到textarea(一般用于异步提交)参数 index: 同上 layedit.getSelection(index) 获取编辑器选中的文本参数 index: 同上 -
编辑器属性设置:
属性 类型 描述 tool Array 重新定制编辑器工具栏,如: tool: [‘link’, ‘unlink’, ‘face’] hideTool Array 不显示编辑器工具栏,一般用于隐藏默认配置的工具bar height Number 设定编辑器的初始高度 uploadImage Object 设定图片上传接口,如:uploadImage: -
富文本编辑器工具栏:
let richtextInex = layedit.build('richtext', { tool: [ 'strong' //加粗 , 'italic' //斜体 , 'underline' //下划线 , 'del' //删除线 , '|' //分割线 , 'left' //左对齐 , 'center' //居中对齐 , 'right' //右对齐 , 'image' //插入图片 ], uploadImage:{url:'/uploadrichtext',type:'POST'} })
评论区